33 changed files with 25299 additions and 6 deletions
@ -0,0 +1,38 @@ |
|||
--- |
|||
title: Git-.gitignore文件不生效 |
|||
author: TianZD |
|||
top: true |
|||
cover: true |
|||
toc: true |
|||
mathjax: false |
|||
summary: >- |
|||
.gitignore中已经标明忽略的文件目录下的文件,git push的时候还会出现在push的目录中,或者用git |
|||
status查看状态,想要忽略的文件还是显示被追踪状态。 |
|||
tags: |
|||
- Git |
|||
categories: |
|||
- Git |
|||
reprintPolicy: cc_by |
|||
abbrlink: 88176b53 |
|||
date: 2022-04-29 10:39:56 |
|||
coverImg: |
|||
img: |
|||
password: |
|||
--- |
|||
|
|||
## 原因 |
|||
在git忽略目录中,新建的文件在git中会有缓存,如果某些文件已经被纳入了版本管理中,就算是在.gitignore中已经声明了忽略路径也是不起作用的,这时候我们就应该先把本地缓存删除,然后再进行git的提交,这样就不会出现忽略的文件了。 |
|||
|
|||
需要特别注意的是: |
|||
1).gitignore只能忽略那些原来没有被track的文件,如果某些文件已经被纳入了版本管理中,则修改.gitignore是无效的。 |
|||
2)想要.gitignore起作用,必须要在这些文件不在暂存区中才可以,.gitignore文件只是忽略没有被staged(cached)文件, |
|||
对于已经被staged文件,加入ignore文件时一定要先从staged移除,才可以忽略。 |
|||
|
|||
## 解决 |
|||
首先清楚本地缓存,将其变为untrack状态,然后提交 |
|||
```bash |
|||
git rm -r --cached . |
|||
git add . |
|||
git commit -m 'update .gitignore' |
|||
git push -u origin master |
|||
``` |
|||
@ -0,0 +1,468 @@ |
|||
--- |
|||
title: Git |
|||
author: TianZD |
|||
top: true |
|||
cover: true |
|||
toc: true |
|||
mathjax: false |
|||
summary: 分布式版本控制工具Git介绍和一些常用操作 |
|||
tags: |
|||
- Git |
|||
- 版本控制 |
|||
categories: |
|||
- Git |
|||
reprintPolicy: cc_by |
|||
abbrlink: 69c3279c |
|||
date: 2022-04-29 10:37:33 |
|||
coverImg: |
|||
img: |
|||
password: |
|||
--- |
|||
|
|||
|
|||
|
|||
[toc] |
|||
|
|||
# Git学习 |
|||
|
|||
# 1、版本控制 |
|||
|
|||
## 版本控制工具 |
|||
|
|||
* Git |
|||
* SVN(Subversion) |
|||
* CVS(Concurrent Version System) |
|||
* VSS(Micorosoft Visual SourceSafe) |
|||
* TFS(Team Foundation Server) |
|||
* Visual Studio Online |
|||
|
|||
Git是目前世界上最先进的分布式**版本控制**系统 |
|||
|
|||
## 分类 |
|||
|
|||
### 本地版本控制 |
|||
|
|||
记录文件每次的更新,可以对每一个版本做一个快照,或是记录补丁文件,适合个人使用,如RCS |
|||
|
|||
 |
|||
|
|||
### 集中版本控制 |
|||
|
|||
代表是SVN |
|||
|
|||
版本库是集中存放在**中央服务器**的,而干活的时候,用的都是自己的电脑,所以要先从中央服务器取得最新的版本,然后开始干活,干完活了,再把自己的活推送给中央服务器。中央服务器就好比是一个图书馆,你要改一本书,必须先从图书馆借出来,然后回到家自己改,改完了,再放回图书馆。**集中式版本控制系统最大的毛病就是必须联网才能工作** |
|||
|
|||
 |
|||
|
|||
### 分布式版本控制 |
|||
|
|||
代表GIT |
|||
|
|||
每个人拥有全部代码,有安全隐患 |
|||
|
|||
分布式版本控制系统根本没有“中央服务器”,每个人的电脑上都是一个完整的版本库,这样,你工作的时候,就不需要联网了,因为版本库就在你自己的电脑上。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你在自己电脑上改了文件A,你的同事也在他的电脑上改了文件A,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。**集中式版本控制系统相比,分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库,某一个人的电脑坏掉了不要紧,随便从其他人那里复制一个就可以了。而集中式版本控制系统的中央服务器要是出了问题,所有人都没法干活了。** |
|||
|
|||
 |
|||
|
|||
|
|||
|
|||
# 2、Git安装 |
|||
|
|||
## Linux安装Git |
|||
|
|||
首先,你可以试着输入git,看看系统有没有安装Git: |
|||
|
|||
``` |
|||
$ git |
|||
The program 'git' is currently not installed. You can install it by typing: |
|||
sudo apt-get install git |
|||
``` |
|||
|
|||
## Macos安装Git |
|||
|
|||
直接从AppStore安装Xcode,Xcode集成了Git,不过默认没有安装,你需要运行Xcode,选择菜单“Xcode”->“Preferences”,在弹出窗口中找到“Downloads”,选择“Command Line Tools”,点“Install”就可以完成安装了。 |
|||
|
|||
## 在Windows上安装Git |
|||
|
|||
在Windows上使用Git,可以从Git官网直接下载安装程序,然后按默认选项安装即可。 |
|||
安装完成后,在开始菜单里找到“Git”->“Git Bash”,蹦出一个类似命令行窗口的东西,就说明Git安装成功。 |
|||
|
|||
## 启动Git |
|||
|
|||
**GIt Bash:**Unix与Linux风格的命令行,使用最多,推荐对坐 |
|||
|
|||
**Git CMD:**Windows风格的命令行 |
|||
|
|||
**Git GUI:**图形界面的Git,不建议使用 |
|||
|
|||
# 3、基本linux命令 |
|||
|
|||
* cd:改变目录 |
|||
* cd .. :回到上一个目录 |
|||
* pwd:查看当前目录 |
|||
* clear:清屏 |
|||
* ls(ll):列出 当前目录所有文件 |
|||
* touch:新建一个文件 |
|||
* rm:删除一个文件 |
|||
* mkdir:新建一个目录 |
|||
* rm -r:删除一个文件夹 |
|||
* rm -rf /:递归删除所有文件 |
|||
* mv:移动文件mv a.html src 把a.html移动到src文件夹下 |
|||
* reset:重新初始化终端/清平 |
|||
* history:查看命令历史 |
|||
* help:帮助 |
|||
* exit:推出 |
|||
* #:注释 |
|||
|
|||
# 4、Git配置 |
|||
|
|||
所有的配置文件都保存在本地 |
|||
|
|||
## 查看配置 |
|||
|
|||
```bash |
|||
git config -l #查看配置 |
|||
git config --system -l #查看系统配置 |
|||
git config --global -l #查看(当前用户)全局配置 |
|||
``` |
|||
|
|||
## 配置用户名和密码 |
|||
|
|||
```bash |
|||
#配置用户名、邮箱 |
|||
git config --global user.name "tianzhendong" |
|||
git config --global user.email 1203886034@qq.com |
|||
``` |
|||
|
|||
# 5、Git原理 |
|||
|
|||
## 工作区域 |
|||
|
|||
* git本地有三个工作区域: |
|||
* 工作目录(working directory):工作区域,平时存放代码的地方 |
|||
* 暂存区(stage/index):用于临时存放你的改动,事实上只是一个文件,保存即将提交到文件列表信息 |
|||
* 资源库(repository或者git directory):本地仓库,安全存放数据的位置,里面有你提交的所有版本的数据,其中HEAD指向最新放入仓库的版本 |
|||
|
|||
* 远程的git仓库(Remote directory):托管代码的服务器 |
|||
|
|||
 |
|||
|
|||
|
|||
|
|||
|
|||
|
|||
 |
|||
|
|||
|
|||
|
|||
## 工作流程 |
|||
|
|||
1. 在工作目录中添加、修改文件 |
|||
2. 将需要进行版本管理的文件放入暂存区 |
|||
3. 将暂存区的文件提交到git仓库 |
|||
4. 提交到远程 |
|||
|
|||
git管理的文件三种状态:已修改(modified)、已暂存(staged)、已提交(committed) |
|||
|
|||
 |
|||
|
|||
# 6、Git使用 |
|||
|
|||
 |
|||
|
|||
## 创建本地仓库 |
|||
|
|||
```bash |
|||
#方法1:创建全新的仓库 |
|||
git init #初始化本地库 |
|||
#方法2:克隆远程仓库到本地 |
|||
git clone [url] #克隆远程仓库到本地 |
|||
``` |
|||
|
|||
## Git文件操作 |
|||
|
|||
文件四种状态: |
|||
|
|||
* **Untracked:**未跟踪,文件在文件夹中,但是没有加入到git库 |
|||
* 通过**git add .**状态变为**staged** |
|||
* **Unmodify:**已入库,未修改 |
|||
* 如果被修改,变为**Modified** |
|||
* 如果使用**git rm**移出版本库则成为**Untracked** |
|||
* **Modified:**已修改 |
|||
* **git add**:进入暂存**staged**状态 |
|||
* **git checkout**:丢弃修改,返回到**unmodify**状态,git checkout即从库中取出文件,覆盖当前修改 |
|||
* **Staged:**暂存状态 |
|||
* **git commit**:修改同步到库中,随后文件变成**unmodify**状态 |
|||
* **git reset HEAD filename**:取消暂存,变为**Modified** |
|||
|
|||
### 基本操作 |
|||
|
|||
```bash |
|||
#查看状态 |
|||
git status |
|||
#查看指定文件状态 |
|||
git status [filename] |
|||
#添加到暂存区 |
|||
git add . |
|||
#提交暂存区内容到本地仓库 |
|||
git commit -m "注释内容" #-m表示提交信息 |
|||
``` |
|||
|
|||
### 忽略文件 |
|||
|
|||
有时候不需要把某些文件纳入版本控制中,比如数据库文件、临时文件、设计文件等 |
|||
|
|||
在主目录下建立".gitignore"文件,此文件有如下规则: |
|||
|
|||
1. 文件中的空行或以#开头的行将会被忽略 |
|||
2. 可以是用linux通配符,例如:*表示任意多个字符,?表示一个字符,[]表示可选字符范围,{}代表可选的字符串集 |
|||
3. 如果名称的最前面有一个!,表示例外规则,将不会被忽略 |
|||
4. 如果名称前面有一个/,表示要忽略的文件在此目录下,子目录下的文件不忽略 |
|||
5. 如果名称的最后面有一个/,表示要忽略的是此目录下的所有文件 |
|||
|
|||
```bash |
|||
#为注释 |
|||
*.txt #忽略所有.txt结尾的文件 |
|||
!lib.txt #lib.txt除外 |
|||
/temp #仅忽略项目根目录下的TODO文件,不包括其他目录temp |
|||
build/ #忽略build/目录下的所有文件 |
|||
doc/*.txt #忽略doc/notes.txt,但不包括doc/server/arch.txt |
|||
``` |
|||
|
|||
## 使用码云Gitee |
|||
|
|||
### 设置本机绑定SSH公钥实现免密登陆 |
|||
|
|||
```bash |
|||
# C:\users\Administrator目录 |
|||
#生成公钥 |
|||
ssh-keygen |
|||
``` |
|||
|
|||
把在.ssh目录下的id_rsa.pub文件中的内容复制到gitee公钥设置中即可 |
|||
|
|||
## IDEA中集成Git |
|||
|
|||
1. 新建项目,绑定git |
|||
1. 将远程的git文件目录拷贝到项目中即可 |
|||
2. 修改文件,使用git |
|||
|
|||
# 7、Git分支 |
|||
|
|||
* **master**:主分支 |
|||
* **dev**:开发用 |
|||
|
|||
master主分支应该非常稳定,用来发布新版本,一般情况下不允许在上面工作,工作一般情况下在新建的dev分支上工作,工作完后,比如要分布,或者说dev分支代码稳定后可以合并到主分支master上来 |
|||
|
|||
三种分支合并情况可以见该链接:https://blog.csdn.net/qq_42780289/article/details/97945300 |
|||
|
|||
```bash |
|||
# 列出所有本地分支 |
|||
git branch |
|||
# 列出所有远程分支 |
|||
git branch -r |
|||
# 新建一个分支,但是并未切换 |
|||
git branch [branch_name] |
|||
# 新建一个分支,并切换至该分支 |
|||
git checkout -b [branch] |
|||
# 合并指定分支到当前分支 |
|||
git merge [branch] |
|||
# 删除分支 |
|||
git branch -d [branch] |
|||
# 删除远程分支 |
|||
git push origin --delete [branch] |
|||
``` |
|||
|
|||
# 8、部分指令 |
|||
|
|||
## 指令 |
|||
|
|||
```bash |
|||
git init //初始化本地库 |
|||
git add readme.txt //将文件添加到仓库 |
|||
git commit -m "first commit" //把文件提交到仓库 |
|||
git status //查看仓库当前状态 |
|||
git diff readme.txt //查看该文件的不同 |
|||
git log // 查看每次更改内容 |
|||
git reset --hard HEAD^ //回退到上一个版本,HEAD表示当前版本,HEAD^上一个版本,几个^号 表示上几个版本; |
|||
rm readme.txt //删除文件 |
|||
git rm readme.txt//从库中删除文件 |
|||
git commit -m "remove the readme.txt" |
|||
git remote add origin git@github.com:michaelliao/learngit.git //关联远程库 |
|||
git push -u origin master //将本地库的内容推送到远程 |
|||
git remote -v //查看远程库信息 |
|||
git remote rm origin //接触本地与远程的绑定关系 |
|||
git clone git@github.com:michaelliao/gitskills.git //从远程库克隆 |
|||
``` |
|||
|
|||
## 合并其他分支代码至master分支 |
|||
|
|||
下面以dev分支为例来讲解。 |
|||
|
|||
1. 当前分支所有代码提交 |
|||
先将dev分支上所有有代码提交至git上,提交的命令一般就是这几个,先复习下: |
|||
|
|||
```bash |
|||
# 将所有代码提交 |
|||
git add . |
|||
# 编写提交备注 |
|||
git commit -m "修改bug" |
|||
# 提交代码至远程分支 |
|||
git push origin dev |
|||
``` |
|||
|
|||
2. 切换当前分支至主干(master) |
|||
|
|||
```bash |
|||
# 切换分支 |
|||
git checkout master |
|||
|
|||
# 如果多人开发建议执行如下命令,拉取最新的代码 |
|||
git pull origin master |
|||
``` |
|||
|
|||
3. 合并(merge)分支代码 |
|||
|
|||
```bash |
|||
git merge dev |
|||
# merge完成后可执行如下命令,查看是否有冲突 |
|||
git status |
|||
``` |
|||
|
|||
4. 提交代码至主干(master) |
|||
|
|||
```bash |
|||
git push origin master |
|||
``` |
|||
|
|||
5. 最后切换回原开发分支 |
|||
|
|||
```bash |
|||
git checkout dev |
|||
``` |
|||
|
|||
## 删除分支 |
|||
|
|||
```bash |
|||
// delete branch locally |
|||
git branch -d localBranchName |
|||
|
|||
// delete branch remotely |
|||
git push origin --delete remoteBranchName |
|||
``` |
|||
|
|||
## 重命名文件 |
|||
|
|||
第一种方法:使用mv命令 |
|||
|
|||
``mv readme README.md`` |
|||
|
|||
这个时候,如果使用git status查看工作区的状态,Git会提示,readme文件被删除,README.md文件未被跟踪。git add进行提交到暂存区的时候,需要把这个两个文件一起提交,即: |
|||
|
|||
``git add readme README.md`` |
|||
|
|||
第二中方法:直接使用Git的 git mv命令。 |
|||
`` |
|||
git mv readme README.md`` |
|||
|
|||
此时,我们不需要再使用git add 命令把两个文件一起提交,直接使用git commit即可。 |
|||
也就是说,git mv命令比linux的mv命令,省去了git add提交文件到暂存区这个步骤。 |
|||
|
|||
|
|||
|
|||
## 【Git】pull遇到错误:error: Your local changes to the following files would be overwritten by merge: |
|||
|
|||
首先取决于你是否想要保存本地修改。(是 /否) |
|||
|
|||
### 是 |
|||
|
|||
别急我们有如下三部曲 |
|||
|
|||
```bash |
|||
git stash |
|||
git pull origin master |
|||
git stash pop |
|||
``` |
|||
|
|||
|
|||
- git stash的时候会把你本地快照,然后git pull 就不会阻止你了,pull完之后这时你的代码并没有保留你的修改。惊了! 别急,我们之前好像做了什么? |
|||
|
|||
STASH |
|||
这时候执行git stash pop你去本地看会发现发生冲突的本地修改还在,这时候你该commit push啥的就悉听尊便了。 |
|||
|
|||
### 否 |
|||
|
|||
既然不想保留本地的修改,那好办。直接将本地的状态恢复到上一个commit id 。然后用远程的代码直接覆盖本地就好了。 |
|||
|
|||
```bash |
|||
git reset --hard |
|||
git pull origin master |
|||
``` |
|||
|
|||
|
|||
|
|||
------------------------------------------------ |
|||
|
|||
版权声明:本文为CSDN博主「转身雪人」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 |
|||
原文链接:https://blog.csdn.net/nakiri_arisu/article/details/80259531 |
|||
|
|||
|
|||
|
|||
# Git 标签 |
|||
|
|||
标签用于标记某一提交点,唯一绑定一个固定的commitId,相当于为这次提交记录指定一个别名,方便提取文件。 |
|||
可以为重要的版本打上标签,标签可以是一个对象,也可以是一个简单的指针,但是指针不会移动。 |
|||
|
|||
## 创建标签 |
|||
|
|||
`git tag <tag_name>` #为当前分支指向的commit记录创建标签 |
|||
|
|||
`git tag <tag_name> <hash_val>` #为指定的commitId创建标签 |
|||
|
|||
`git tag -a <tag_name> -m "msg" <hash_val>` #创建标签同时添加说明信息 |
|||
|
|||
## 查看标签 |
|||
|
|||
`git tag` #查看所有标签名称 |
|||
|
|||
`git show <tag_name>` #查看标签的详细信息(包含commit的信息) |
|||
|
|||
`git tag -ln [tag_name]` #显示标签名及其描述信息 |
|||
|
|||
## 远程推送标签 |
|||
|
|||
`git push <remote_name> <tag_name>` #将标签推送到远程服务器 |
|||
|
|||
`git push <remote_name> --tags` #将本地的全部tag推送到远程服务器 |
|||
|
|||
## 删除标签 |
|||
|
|||
`git tag -d <tag_name>` #删除本地的标签 |
|||
|
|||
`git push <remote_name> :refs/tags/<tag_name>` #删除远程标签 |
|||
|
|||
## 标签内容提取 |
|||
|
|||
``` |
|||
git archive --format=zip --output=src/xxx.zip <tag_name>` #提取为zip格式,src可以是相对路径,也可以是绝对路径 |
|||
**示例:**在d盘下生成包含0.8标签内容的压缩包 |
|||
`git archive --format=zip --output=d:/v0.8.zip v0.8 |
|||
``` |
|||
|
|||
## 切换标签 |
|||
|
|||
如果我们不想直接提取出标签的代码,而是希望在指定标签下继续进行开发,此时可以切换到标签。 |
|||
|
|||
`git checkout <tag_name>` #切换到指定标签 |
|||
|
|||
**示例:**切换到v0.8标签进行开发,此时提示我们处于`detached HEAD state`(分离头指针状态),即说明HEAD指针没有指向具体的分支,查看HEAD指针它直接指向了一个commit对象,此时进行开发操作没有任何意义。 |
|||
|
|||
如果想要退出`detached HEAD state`,很简单只需要切换回指定分支就可以了,如`git checkout master` |
|||
|
|||
如果想要在当前tag下继续开发,可以新建一个分支并让HEAD指向分支就可以了。 |
|||
|
|||
|
|||
|
|||
## 强制推送 |
|||
|
|||
`git push -f origin master`强制推送到origin远程的master分支上 |
|||
File diff suppressed because it is too large
File diff suppressed because it is too large
File diff suppressed because it is too large
@ -0,0 +1,921 @@ |
|||
--- |
|||
title: SSM整合 |
|||
author: TianZD |
|||
top: true |
|||
cover: true |
|||
toc: true |
|||
mathjax: false |
|||
summary: SSM整合学习笔记,粗略学了一下,没有参考价值 |
|||
tags: |
|||
- SSM |
|||
- Java |
|||
- 学习笔记 |
|||
categories: |
|||
- java |
|||
reprintPolicy: cc_by |
|||
abbrlink: 254393f0 |
|||
date: 2022-04-29 11:10:43 |
|||
coverImg: |
|||
img: |
|||
password: |
|||
--- |
|||
|
|||
|
|||
|
|||
[toc] |
|||
|
|||
|
|||
|
|||
# 1、SpringMVC-SSM整合 |
|||
|
|||
## 1.1、环境 |
|||
|
|||
> 环境 |
|||
|
|||
* IDE:IDEA 2021 1.1 |
|||
* 项目管理:Maven ,apache-maven-3.8.1 |
|||
* JAVA:JDK 16.01 |
|||
* Web服务器:apache-tomcat-9.0.50 |
|||
* 数据库:MySQL 8.0.26 |
|||
* 数据库管理工具:Navicat premium 15 |
|||
|
|||
> 数据库环境 |
|||
|
|||
```sql |
|||
CREATE DATABASE `ssmbuild`; |
|||
USE `ssmbuild`; |
|||
DROP TABLE IF EXISTS `books`; |
|||
CREATE TABLE `books` ( |
|||
`bookID` INT(10) NOT NULL AUTO_INCREMENT COMMENT '书id', |
|||
`bookName` VARCHAR(100) NOT NULL COMMENT '书名', |
|||
`bookCounts` INT(11) NOT NULL COMMENT '数量', |
|||
`detail` VARCHAR(200) NOT NULL COMMENT '描述', |
|||
KEY `bookID` (`bookID`) |
|||
)ENGINE = INNODB DEFAULT CHARSET = utf8; |
|||
|
|||
INSERT INTO `books`(`bookID`,`bookName`,`bookCounts`,`detail`) |
|||
VALUES (1,'java',1,'从入门到放弃'), |
|||
(2,'MySQL',10,'从删库到跑路'), |
|||
(3,'Linux',5,'从进门到坐牢'); |
|||
``` |
|||
|
|||
> 基本环境搭建 |
|||
|
|||
* 新建maven工程 |
|||
* 配置pom.xml |
|||
* 导入依赖 |
|||
* 配置静态资源 |
|||
|
|||
```xml |
|||
<!--依赖:junit,数据库驱动,连接池,servlet,jsp,mybatis,mybatis-spring,spring,log4j--> |
|||
<dependencies> |
|||
<!--junit--> |
|||
<dependency> |
|||
<groupId>junit</groupId> |
|||
<artifactId>junit</artifactId> |
|||
<version>4.12</version> |
|||
<scope>test</scope> |
|||
</dependency> |
|||
<!--数据库驱动--> |
|||
<dependency> |
|||
<groupId>mysql</groupId> |
|||
<artifactId>mysql-connector-java</artifactId> |
|||
<version>8.0.25</version> |
|||
</dependency> |
|||
<!--数据库连接池c3p0或者dpcp--> |
|||
<dependency> |
|||
<groupId>com.mchange</groupId> |
|||
<artifactId>c3p0</artifactId> |
|||
<version>0.9.5.2</version> |
|||
</dependency> |
|||
<!--servlet jsp--> |
|||
<dependency> |
|||
<groupId>javax.servlet</groupId> |
|||
<artifactId>servlet-api</artifactId> |
|||
<version>2.5</version> |
|||
</dependency> |
|||
<dependency> |
|||
<groupId>javax.servlet.jsp</groupId> |
|||
<artifactId>jsp-api</artifactId> |
|||
<version>2.2</version> |
|||
</dependency> |
|||
<dependency> |
|||
<groupId>javax.servlet</groupId> |
|||
<artifactId>jstl</artifactId> |
|||
<version>1.2</version> |
|||
</dependency> |
|||
<!--mybatis--> |
|||
<dependency> |
|||
<groupId>org.mybatis</groupId> |
|||
<artifactId>mybatis</artifactId> |
|||
<version>3.5.7</version> |
|||
</dependency> |
|||
<!--mybatis-spring--> |
|||
<dependency> |
|||
<groupId>org.mybatis</groupId> |
|||
<artifactId>mybatis-spring</artifactId> |
|||
<version>2.0.2</version> |
|||
</dependency> |
|||
<!--spring--> |
|||
<dependency> |
|||
<groupId>org.springframework</groupId> |
|||
<artifactId>spring-webmvc</artifactId> |
|||
<version>5.3.9</version> |
|||
</dependency> |
|||
<dependency> |
|||
<groupId>org.springframework</groupId> |
|||
<artifactId>spring-jdbc</artifactId> |
|||
<version>5.3.9</version> |
|||
</dependency> |
|||
|
|||
<!--log4j--> |
|||
<dependency> |
|||
<groupId>log4j</groupId> |
|||
<artifactId>log4j</artifactId> |
|||
<version>1.2.17</version> |
|||
</dependency> |
|||
</dependencies> |
|||
|
|||
|
|||
<!--静态资源导出问题--> |
|||
<build> |
|||
<resources> |
|||
<resource> |
|||
<directory>src/main/java</directory> |
|||
<includes> |
|||
<include>**/*.properties</include> |
|||
<include>**/*.xml</include> |
|||
</includes> |
|||
<filtering>false</filtering> |
|||
</resource> |
|||
<resource> |
|||
<directory>src/main/resources</directory> |
|||
<includes> |
|||
<include>**/*.properties</include> |
|||
<include>**/*.xml</include> |
|||
</includes> |
|||
<filtering>false</filtering> |
|||
</resource> |
|||
</resources> |
|||
</build> |
|||
``` |
|||
|
|||
> IDEA连接数据库 |
|||
|
|||
 |
|||
|
|||
> 建立项目包结构 |
|||
|
|||
* dao |
|||
* pojo |
|||
* controller |
|||
* service |
|||
|
|||
> 建立核心配置文件 |
|||
|
|||
* spring:applicationContext.xml |
|||
|
|||
```xml |
|||
<?xml version="1.0" encoding="UTF-8"?> |
|||
<beans xmlns="http://www.springframework.org/schema/beans" |
|||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" |
|||
xmlns:context="http://www.springframework.org/schema/context" |
|||
xsi:schemaLocation="http://www.springframework.org/schema/beans |
|||
http://www.springframework.org/schema/beans/spring-beans.xsd |
|||
http://www.springframework.org/schema/context |
|||
http://www.springframework.org/schema/context/spring-context-4.0.xsd"> |
|||
|
|||
</beans> |
|||
``` |
|||
|
|||
* mybatis:mybatis-config.xml和database.properties |
|||
|
|||
mybatis-config.xml |
|||
|
|||
```xml |
|||
<?xml version="1.0" encoding="UTF-8" ?> |
|||
<!DOCTYPE configuration |
|||
PUBLIC "-//mybatis.org//DTD Config 3.0//EN" |
|||
"http://mybatis.org/dtd/mybatis-3-config.dtd"> |
|||
<configuration> |
|||
|
|||
<settings> |
|||
<!--配置log4j,name必须为logImpl,I为大写,value需要使用mybatis提供的哪些,不能有空格--> |
|||
<setting name="logImpl" value="LOG4J"/> |
|||
</settings> |
|||
<!--配置数据源,交给spring了--> |
|||
|
|||
<!--配置别名--> |
|||
<typeAliases> |
|||
<package name="com.tian.pojo"/> |
|||
</typeAliases> |
|||
|
|||
</configuration> |
|||
``` |
|||
|
|||
database.properties |
|||
|
|||
```properties |
|||
jdbc.driver=com.mysql.cj.jdbc.Driver |
|||
#如果使用mysql8.0以上,需要增加时区设置 |
|||
jdbc.url=jdbc:mysql://localhost:3306/ssmbuild?useSSL=true&useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai |
|||
jdbc.username=root |
|||
jdbc.password=123456 |
|||
``` |
|||
|
|||
* log4j.properties |
|||
|
|||
```properties |
|||
#将等级为DEBUG的日志信息输出到console和file这两个目的地,console和file的定义在下面的代码 |
|||
log4j.rootLogger=DEBUG,console,file |
|||
|
|||
#控制台输出的相关设置 |
|||
log4j.appender.console = org.apache.log4j.ConsoleAppender |
|||
log4j.appender.console.Target = System.out |
|||
log4j.appender.console.Threshold=DEBUG |
|||
log4j.appender.console.layout = org.apache.log4j.PatternLayout |
|||
log4j.appender.console.layout.ConversionPattern=[%c]-%m%n |
|||
|
|||
#文件输出的相关设置 |
|||
log4j.appender.file = org.apache.log4j.RollingFileAppender |
|||
log4j.appender.file.File=./log/tian.log |
|||
log4j.appender.file.MaxFileSize=10mb |
|||
log4j.appender.file.Threshold=DEBUG |
|||
log4j.appender.file.layout=org.apache.log4j.PatternLayout |
|||
log4j.appender.file.layout.ConversionPattern=[%p][%d{yy-MM-dd}][%c]%m%n |
|||
|
|||
#日志输出级别 |
|||
log4j.logger.org.mybatis=DEBUG |
|||
log4j.logger.java.sql=DEBUG |
|||
log4j.logger.java.sql.Statement=DEBUG |
|||
log4j.logger.java.sql.ResultSet=DEBUG |
|||
log4j.logger.java.sql.PreparedStatement=DEBUG |
|||
``` |
|||
|
|||
## 1.2、Mybatis层 |
|||
|
|||
主要是dao层和service层,底层相关,MVC的Model层,数据和业务 |
|||
|
|||
|
|||
|
|||
> pojo层 |
|||
|
|||
```java |
|||
public class Books { |
|||
private int bookID; |
|||
private String bookName; |
|||
private int bookCounts; |
|||
private String detail; |
|||
//get、set、toString、construct |
|||
} |
|||
``` |
|||
|
|||
> dao层 |
|||
|
|||
* 接口 |
|||
|
|||
```java |
|||
public interface BookMapper { |
|||
//add |
|||
int addBook(Books books); |
|||
|
|||
//delete |
|||
int deleteBook(@Param("bookID") int id); |
|||
|
|||
//update |
|||
int updateBook(Books books); |
|||
|
|||
//select one |
|||
Books selectBookById(@Param("bookID") int id); |
|||
|
|||
//select all |
|||
List<Books> selectBookAll(); |
|||
} |
|||
``` |
|||
|
|||
* Mapper.xml |
|||
|
|||
```xml |
|||
<?xml version="1.0" encoding="UTF-8" ?> |
|||
<!DOCTYPE mapper |
|||
PUBLIC "-//mybatis.org//DTD Config 3.0//EN" |
|||
"http://mybatis.org/dtd/mybatis-3-mapper.dtd"> |
|||
<mapper namespace="com.tian.dao.BookMapper"> |
|||
<insert id="addBook" parameterType="books"> |
|||
insert into ssmbuild.books (bookName, bookCounts, detail) |
|||
values (#{bookName},#{bookCounts},#{detail}); |
|||
</insert> |
|||
|
|||
<delete id="deleteBook" parameterType="int"> |
|||
delete |
|||
from ssmbuild.books |
|||
where bookID = #{bookID}; |
|||
</delete> |
|||
|
|||
<update id="updateBook" parameterType="books"> |
|||
update ssmbuild.books |
|||
set bookName = #{bookName}, bookCounts = #{bookCounts}, detail = #{detail} |
|||
where bookID = #{bookID}; |
|||
</update> |
|||
|
|||
<select id="selectBookById" resultType="books"> |
|||
select * |
|||
from ssmbuild.books |
|||
where bookID = #{bookID}; |
|||
</select> |
|||
|
|||
<select id="selectBookAll" resultType="books"> |
|||
select * |
|||
from ssmbuild.books; |
|||
</select> |
|||
|
|||
</mapper> |
|||
``` |
|||
|
|||
* 绑定mapper.xml到mybatis-config.xml配置文件中 |
|||
|
|||
```xml |
|||
<mappers> |
|||
<mapper class="com.tian.dao.BookMapper"/> |
|||
<!-- <mapper resource="com/tian/dao/BookMapper.xml"/>--> |
|||
<!-- <package name="com.tian.dao"/>--> |
|||
</mappers> |
|||
``` |
|||
|
|||
> service层 |
|||
|
|||
* BookService接口 |
|||
|
|||
```java |
|||
public interface BookService { |
|||
//add |
|||
int addBook(Books books); |
|||
|
|||
//delete |
|||
int deleteBook(int id); |
|||
|
|||
//update |
|||
int updateBook(Books books); |
|||
|
|||
//select one |
|||
Books selectBookById(int id); |
|||
|
|||
//select all |
|||
List<Books> selectBookAll(); |
|||
} |
|||
``` |
|||
|
|||
|
|||
|
|||
* 接口实现类 |
|||
|
|||
```java |
|||
public class BookServiceImpl implements BookService{ |
|||
//业务层调用dao层:组合dao层 |
|||
private BookMapper bookMapper; |
|||
|
|||
public void setBookMapper(BookMapper bookMapper) { |
|||
this.bookMapper = bookMapper; |
|||
} |
|||
|
|||
@Override |
|||
public int addBook(Books books) { |
|||
return bookMapper.addBook(books); |
|||
} |
|||
|
|||
@Override |
|||
public int deleteBook(int id) { |
|||
return bookMapper.deleteBook(id); |
|||
} |
|||
|
|||
@Override |
|||
public int updateBook(Books books) { |
|||
return bookMapper.updateBook(books); |
|||
} |
|||
|
|||
@Override |
|||
public Books selectBookById(int id) { |
|||
return bookMapper.selectBookById(id); |
|||
} |
|||
|
|||
@Override |
|||
public List<Books> selectBookAll() { |
|||
return bookMapper.selectBookAll(); |
|||
} |
|||
} |
|||
``` |
|||
|
|||
## 1.3、Spring层 |
|||
|
|||
> dao层 |
|||
|
|||
spring-dao.xml |
|||
|
|||
* 关联数据库配置文件 |
|||
* 连接池 |
|||
* sqlSessionFactory |
|||
* sqlSession |
|||
|
|||
```xml |
|||
<?xml version="1.0" encoding="UTF-8"?> |
|||
<beans xmlns="http://www.springframework.org/schema/beans" |
|||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" |
|||
xmlns:context="http://www.springframework.org/schema/context" |
|||
xsi:schemaLocation="http://www.springframework.org/schema/beans |
|||
http://www.springframework.org/schema/beans/spring-beans.xsd |
|||
http://www.springframework.org/schema/context |
|||
http://www.springframework.org/schema/context/spring-context-4.0.xsd"> |
|||
|
|||
<!--关联数据库配置文件--> |
|||
<context:property-placeholder location="classpath:database.properties"/> |
|||
|
|||
<!--连接池 |
|||
dbcp:半自动化操作,不能自动连接 |
|||
c3p0:自动化链接(自动化加载配置文件,并且可以自动设置到对象中) |
|||
druid |
|||
hikari--> |
|||
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"> |
|||
<property name="driverClass" value="${jdbc.driver}"/> |
|||
<property name="jdbcUrl" value="${jdbc.url}"/> |
|||
<property name="user" value="${jdbc.username}"/> |
|||
<property name="password" value="${jdbc.password}"/> |
|||
<!--c3p0连接池的私有属性--> |
|||
<property name="maxPoolSize" value="30"/> |
|||
<property name="minPoolSize" value="10"/> |
|||
<!--关闭连接后不自动commit--> |
|||
<property name="autoCommitOnClose" value="false"/> |
|||
<!--获取连接超时时间--> |
|||
<property name="checkoutTimeout" value="100000"/> |
|||
<!--当前连接失败重试次数--> |
|||
<property name="acquireRetryAttempts" value="2"/> |
|||
</bean> |
|||
|
|||
<!--sqlSessionFactory--> |
|||
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> |
|||
<property name="dataSource" ref="dataSource"/> |
|||
<!--绑定mybatis配置文件--> |
|||
<property name="configLocation" value="classpath:mybatis-config.xml"/> |
|||
</bean> |
|||
|
|||
<!--采用方法3 |
|||
方法1:dao编写BookMapper实现类,添加SqlSessionTemplate属性 |
|||
方法2:dao编写BookMapper实现类,同时继承SqlSessionDaoSupport,通过get方法可以直接获的sqlSession |
|||
方法3:配置dao扫描包,动态的实现了dao接口可以注入到spring容器中--> |
|||
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> |
|||
<!--注入sqlsession,由于属性为string,用value--> |
|||
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/> |
|||
<!--要扫描的dao包--> |
|||
<property name="basePackage" value="com.tian.dao"/> |
|||
</bean> |
|||
</beans> |
|||
``` |
|||
|
|||
> service |
|||
|
|||
spring-service.xml |
|||
|
|||
* 扫描service下的包 |
|||
* 将业务类注入到spring,可以通过配置或者注解实现 |
|||
* 声明式事务配置 |
|||
* AOP事务支持 |
|||
|
|||
```xml |
|||
<?xml version="1.0" encoding="UTF-8"?> |
|||
<beans xmlns="http://www.springframework.org/schema/beans" |
|||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" |
|||
xmlns:context="http://www.springframework.org/schema/context" |
|||
xsi:schemaLocation="http://www.springframework.org/schema/beans |
|||
http://www.springframework.org/schema/beans/spring-beans.xsd |
|||
http://www.springframework.org/schema/context |
|||
http://www.springframework.org/schema/context/spring-context-4.0.xsd"> |
|||
|
|||
<!--扫描service下的包--> |
|||
<context:component-scan base-package="com.tian.service"/> |
|||
|
|||
<!--将业务类注入到spring,可以通过配置或者注解实现 |
|||
注解:类上@Service 属性上@Autowired--> |
|||
<bean id="BookServiceImpl" class="com.tian.service.BookServiceImpl"> |
|||
<property name="bookMapper" ref="bookMapper"/> |
|||
</bean> |
|||
|
|||
<!--声明式事务配置--> |
|||
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> |
|||
<!--注入数据源--> |
|||
<property name="dataSource" ref="dataSource"/> |
|||
</bean> |
|||
|
|||
<!--AOP事务支持--> |
|||
</beans> |
|||
``` |
|||
|
|||
## 1.4、SpringMVC层 |
|||
|
|||
> 增加web支持 |
|||
|
|||
> web.xml |
|||
|
|||
* dispatchservlet |
|||
* 乱码过滤 |
|||
|
|||
```xml |
|||
<?xml version="1.0" encoding="UTF-8"?> |
|||
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" |
|||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" |
|||
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd" |
|||
version="4.0"> |
|||
|
|||
<!--DispatchServlet--> |
|||
<servlet> |
|||
<servlet-name>dispatcherServlet</servlet-name> |
|||
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> |
|||
<!-- 关联配置文件 --> |
|||
<init-param> |
|||
<param-name>contextConfigLocation</param-name> |
|||
<param-value>classpath:springmvc-servlet.xml</param-value> |
|||
</init-param> |
|||
<!-- 启动优先级:越小越优先启动 --> |
|||
<load-on-startup>1</load-on-startup> |
|||
</servlet> |
|||
<servlet-mapping> |
|||
<servlet-name>dispatcherServlet</servlet-name> |
|||
<url-pattern>/</url-pattern> |
|||
</servlet-mapping> |
|||
|
|||
<!--乱码过滤--> |
|||
<filter> |
|||
<filter-name>encodingFilter</filter-name> |
|||
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class> |
|||
<init-param> |
|||
<param-name>encoding</param-name> |
|||
<param-value>utf-8</param-value> |
|||
</init-param> |
|||
</filter> |
|||
<filter-mapping> |
|||
<filter-name>encodingFilter</filter-name> |
|||
<url-pattern>/*</url-pattern> |
|||
</filter-mapping> |
|||
|
|||
<!--session--> |
|||
<session-config> |
|||
<session-timeout>15</session-timeout> |
|||
</session-config> |
|||
|
|||
</web-app> |
|||
``` |
|||
|
|||
> springmvc-servlet.xml |
|||
|
|||
```xml |
|||
<?xml version="1.0" encoding="UTF-8"?> |
|||
<beans xmlns="http://www.springframework.org/schema/beans" |
|||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" |
|||
xmlns:context="http://www.springframework.org/schema/context" |
|||
xmlns:mvc="http://www.springframework.org/schema/mvc" |
|||
xsi:schemaLocation="http://www.springframework.org/schema/beans |
|||
http://www.springframework.org/schema/beans/spring-beans.xsd |
|||
http://www.springframework.org/schema/context |
|||
http://www.springframework.org/schema/context/spring-context-4.0.xsd |
|||
http://www.springframework.org/schema/mvc |
|||
https://www.springframework.org/schema/mvc/spring-mvc.xsd"> |
|||
|
|||
<!-- 扫描包 --> |
|||
<context:component-scan base-package="com.tian.controller"/> |
|||
<!-- 过滤静态资源 --> |
|||
<mvc:default-servlet-handler/> |
|||
<!-- 注解驱动 --> |
|||
<mvc:annotation-driven/> |
|||
|
|||
<!-- 视图解析器 --> |
|||
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver" |
|||
id="internalResourceViewResolver"> |
|||
<!-- 前缀 --> |
|||
<property name="prefix" value="/WEB-INF/jsp/"/> |
|||
<!-- 后缀 --> |
|||
<property name="suffix" value=".jsp"/> |
|||
</bean> |
|||
</beans> |
|||
``` |
|||
|
|||
## 1.5、配置文件整合 |
|||
|
|||
applicationContext.xml |
|||
|
|||
```xml |
|||
<?xml version="1.0" encoding="UTF-8"?> |
|||
<beans xmlns="http://www.springframework.org/schema/beans" |
|||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" |
|||
xmlns:context="http://www.springframework.org/schema/context" |
|||
xsi:schemaLocation="http://www.springframework.org/schema/beans |
|||
http://www.springframework.org/schema/beans/spring-beans.xsd |
|||
http://www.springframework.org/schema/context |
|||
http://www.springframework.org/schema/context/spring-context-4.0.xsd"> |
|||
|
|||
<import resource="spring-dao.xml"/> |
|||
<import resource="spring-service.xml"/> |
|||
<import resource="springmvc-servlet.xml"/> |
|||
</beans> |
|||
``` |
|||
|
|||
# 2、实际业务实现 |
|||
|
|||
## 2.1、查询书籍功能 |
|||
|
|||
### 查询 |
|||
|
|||
将controller和web交互 |
|||
|
|||
> controller |
|||
|
|||
*BookController.class* |
|||
|
|||
```java |
|||
@Controller |
|||
@RequestMapping("/book") |
|||
public class BookController { |
|||
//controller层调用service层 |
|||
@Autowired |
|||
@Qualifier("BookServiceImpl") |
|||
private BookService bookService; |
|||
|
|||
//查询全部书籍,并返回书籍展示页面 |
|||
public String selectAllBook(Model model) { |
|||
List<Books> books = bookService.selectBookAll(); |
|||
model.addAttribute("list", books); |
|||
return "allBook"; |
|||
} |
|||
|
|||
} |
|||
``` |
|||
|
|||
> jsp |
|||
|
|||
* allBook.jsp |
|||
* index.jsp,设置由首页跳转 |
|||
|
|||
```jsp |
|||
<%@ page contentType="text/html;charset=UTF-8" language="java" %> |
|||
<html> |
|||
<head> |
|||
<title>书籍展示</title> |
|||
</head> |
|||
<body> |
|||
<h1>书籍展示</h1> |
|||
</body> |
|||
</html> |
|||
``` |
|||
|
|||
```jsp |
|||
<%@ page contentType="text/html;charset=UTF-8" language="java" %> |
|||
<html> |
|||
<head> |
|||
<title>$Title$</title> |
|||
</head> |
|||
<body> |
|||
$END$ |
|||
<h3> |
|||
<a href="${pageContext.request.contextPath}/book/allBook">进入书籍展示页面</a> |
|||
</h3> |
|||
</body> |
|||
</html> |
|||
``` |
|||
|
|||
### 错误 |
|||
|
|||
```bash |
|||
org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type 'com.tian.service.BookService' available: expected at least 1 bean which qualifies as autowire candidate. Dependency annotations: {@org.springframework.beans.factory.annotation.Autowired(required=true), @org.springframework.beans.factory.annotation.Qualifier("BookServiceImpl")} |
|||
``` |
|||
|
|||
bean不存在 |
|||
|
|||
> 解决 |
|||
|
|||
web.xml中需要引入applicationContxt.xml而不是springmvc-config.xml |
|||
|
|||
### 美化 |
|||
|
|||
> 首页 |
|||
|
|||
```jsp |
|||
<%@ page contentType="text/html;charset=UTF-8" language="java" %> |
|||
<html> |
|||
<head> |
|||
<title>首页</title> |
|||
<style> |
|||
a { |
|||
text-decoration: none; |
|||
color: black; |
|||
font-size: 18px; |
|||
} |
|||
h3 { |
|||
width: 180px; |
|||
height: 38px; |
|||
margin: 100px auto; |
|||
text-align: center; |
|||
line-height: 38px; |
|||
background: deepskyblue; |
|||
border-radius: 5px; |
|||
} |
|||
</style> |
|||
</head> |
|||
<body> |
|||
<h3> |
|||
<a href="${pageContext.request.contextPath}/book/allBook">进入书籍展示页面</a> |
|||
</h3> |
|||
</body> |
|||
</html> |
|||
``` |
|||
|
|||
 |
|||
|
|||
> 查询页 |
|||
|
|||
```jsp |
|||
<%@ page contentType="text/html;charset=UTF-8" language="java" %> |
|||
<html> |
|||
<head> |
|||
<title>书籍展示</title> |
|||
</head> |
|||
<body> |
|||
<table align="center" border="1" width="300" height="100" cellspacing="0"><!--设置表格剧中,边框线粗细,每个格子的长宽,单元格之间的间距为0--> |
|||
<tr align="center"> |
|||
<th colspan="4" bgcolor="#00bfff">书籍列表</th><!--表头,自带加粗居中属性,colspan设置合并1行1列和2列的单元格,rowspan设置跨列合并--> |
|||
</tr> |
|||
<tr bgcolor="#ffe4c4"> |
|||
<td align="center"><b>书籍ID</b></td><!--设置字体居中,加粗--> |
|||
<td align="center"><b>书籍名称</b></td> |
|||
<td align="center"><b>书籍数量</b></td> |
|||
<td align="center"><b>书籍描述</b></td> |
|||
</tr> |
|||
<c:forEach var="books" items="${list}"> |
|||
<tr align="center" bgcolor="#a9a9a9"> |
|||
<td>${books.bookID}</td> |
|||
<td>${books.bookName}</td> |
|||
<td>${books.bookCounts}</td> |
|||
<td>${books.detail}</td> |
|||
</tr> |
|||
</c:forEach> |
|||
</table> |
|||
</body> |
|||
</html> |
|||
``` |
|||
|
|||
 |
|||
|
|||
## 2.2、添加书籍功能 |
|||
|
|||
> 待跳转页面 |
|||
|
|||
addBook.jsp |
|||
|
|||
```jsp |
|||
<%@ page contentType="text/html;charset=UTF-8" language="java" %> |
|||
<html> |
|||
<head> |
|||
<title>添加书籍页面</title> |
|||
</head> |
|||
<body> |
|||
<form action="${pageContext.request.contextPath}/book/addBook" method="post"> |
|||
<table align="center" border="0"> |
|||
<tr> |
|||
<td>书籍名称: </td> |
|||
<td><input type="text" name="书籍名称" required></td> |
|||
</tr> |
|||
<tr> |
|||
<td>书籍数量: </td> |
|||
<td><input type="text" name="书籍数量" required></td> |
|||
</tr> |
|||
<tr> |
|||
<td>书籍描述: </td> |
|||
<td><input type="text" name="书籍描述"></td> |
|||
</tr> |
|||
<tr align="center"> |
|||
<td><input type="reset" value="重置"></td> |
|||
<td><input type="submit" value="添加"></td> |
|||
</tr> |
|||
</table> |
|||
</form> |
|||
</body> |
|||
</html> |
|||
``` |
|||
|
|||
 |
|||
|
|||
> controller |
|||
|
|||
```java |
|||
// 跳转到添加书籍界面 |
|||
@RequestMapping("/toAddBook") |
|||
public String toAddBook() { |
|||
return "addBook"; |
|||
} |
|||
|
|||
//添加书籍请求 |
|||
@RequestMapping("/addBook") |
|||
public String addBook(Books book) { |
|||
bookService.addBook(book); |
|||
return "redirect:/book/allBook"; |
|||
} |
|||
``` |
|||
|
|||
> 跳转按钮 |
|||
|
|||
allBook.jsp |
|||
|
|||
```xml |
|||
<style> |
|||
#a1{ |
|||
text-decoration: none; |
|||
} |
|||
</style> |
|||
|
|||
<tr> |
|||
<td colspan="4" align="center"><a id="a1" href="${pageContext.request.contextPath}/book/toAddBook">添加书籍</a></td> |
|||
</tr> |
|||
``` |
|||
|
|||
 |
|||
|
|||
## 2.3、修改、删除书籍 |
|||
|
|||
> 按钮 |
|||
|
|||
allBook.jsp |
|||
|
|||
```jsp |
|||
<td> |
|||
<a href="${pageContext.request.contextPath}/book/toUpdateBook/${books.bookID}">修改</a> |
|||
| |
|||
<a href="${pageContext.request.contextPath}/book/deleteBook/${books.bookID}">删除</a> |
|||
</td> |
|||
``` |
|||
|
|||
 |
|||
|
|||
> controller |
|||
|
|||
```java |
|||
//跳转到修改请求页面 |
|||
@RequestMapping("/toUpdateBook/{bookId}") |
|||
public String toUpdateBook(@PathVariable("bookId") int id, Model model) { |
|||
Books books = bookService.selectBookById(id); |
|||
model.addAttribute("bookSelected", books); |
|||
return "updateBook"; |
|||
} |
|||
|
|||
//修改书籍 |
|||
@RequestMapping("/updateBook") |
|||
public String updateBook(Books books) { |
|||
bookService.updateBook(books); |
|||
return "redirect:/book/allBook"; |
|||
} |
|||
|
|||
//删除书籍 |
|||
@RequestMapping("/deleteBook/{bookId}") |
|||
public String deleteBook(@PathVariable("bookId") int id) { |
|||
bookService.deleteBook(id); |
|||
return "redirect:/book/allBook"; |
|||
} |
|||
} |
|||
``` |
|||
|
|||
> 待跳转页面 |
|||
|
|||
updateBook.jsp |
|||
|
|||
```jsp |
|||
<%@ page contentType="text/html;charset=UTF-8" language="java" %> |
|||
<html> |
|||
<head> |
|||
<title>修改书籍</title> |
|||
</head> |
|||
<body> |
|||
<form action="${pageContext.request.contextPath}/book/updateBook" method="post"> |
|||
<%--隐藏于传递不需要用户修改的bookID--%> |
|||
<input type="hidden" name="bookID" value="${bookSelected.bookID}"> |
|||
<table align="center" border="0"> |
|||
<tr> |
|||
<td>书籍名称: </td> |
|||
<td><input type="text" name="bookName" value="${bookSelected.bookName}" required></td> |
|||
</tr> |
|||
<tr> |
|||
<td>书籍数量: </td> |
|||
<td><input type="text" name="bookCounts" value="${bookSelected.bookCounts}" required></td> |
|||
</tr> |
|||
<tr> |
|||
<td>书籍描述: </td> |
|||
<td><input type="text" name="detail" value="${bookSelected.detail}"></td> |
|||
</tr> |
|||
<tr align="center"> |
|||
<td><input type="reset" value="重置"></td> |
|||
<td><input type="submit" value="修改"></td> |
|||
</tr> |
|||
</table> |
|||
</form> |
|||
</body> |
|||
</html> |
|||
``` |
|||
|
|||
 |
|||
|
|||
|
|||
|
|||
File diff suppressed because it is too large
File diff suppressed because it is too large
File diff suppressed because it is too large
File diff suppressed because it is too large
@ -0,0 +1,247 @@ |
|||
--- |
|||
title: VUE学习 |
|||
author: TianZD |
|||
top: true |
|||
cover: true |
|||
toc: true |
|||
mathjax: false |
|||
summary: 前端框架VUE学习笔记,粗略学习了一下,没有参考价值 |
|||
tags: |
|||
- 前端 |
|||
- VUE |
|||
- 学习笔记 |
|||
categories: |
|||
- 前端 |
|||
reprintPolicy: cc_by |
|||
abbrlink: 7b0d284 |
|||
date: 2022-04-29 10:54:08 |
|||
coverImg: |
|||
img: |
|||
password: |
|||
--- |
|||
|
|||
|
|||
[toc] |
|||
|
|||
# VUE |
|||
|
|||
# 1、前端 |
|||
|
|||
## 1.1、前端概述 |
|||
|
|||
### 什么是前端 |
|||
|
|||
* 前端:针对浏览器的开发,代码在浏览器运行 |
|||
* 后端:针对服务器的开发,代码在服务器运行 |
|||
|
|||
### 前端三剑客 |
|||
|
|||
* HTML |
|||
* CSS |
|||
* JavaScript |
|||
|
|||
> HTML |
|||
|
|||
HTML(超文本标记语言——HyperText Markup Language)是构成 Web 世界的基石。HTML是一种基础技术,常与CSS、JavaScript一起被众多网站用于设计令人赏心悦目的网页、网页应用程序以及移动应用程序的用户界面。 |
|||
超文本标记语言(第一版)——在1993年6月作为互联网工程工作小组(IETF)工作草案发布(并非标准): |
|||
HTML 2.0——1995年11月作为RFC 1866发布,在RFC 2854于2000年6月发布之后被宣布已经过时 |
|||
HTML 3.2——1997年1月14日,W3C推荐标准 |
|||
HTML 4.0——1997年12月18日,W3C推荐标准 |
|||
HTML 4.01(微小改进)——1999年12月24日,W3C推荐标准 |
|||
HTML 5——2014年10月28日,W3C推荐标准 |
|||
|
|||
> CSS |
|||
|
|||
层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML(标准通用标记语言的一个应用)或XML(标准通用标记语言的一个子集)等文件样式的计算机语言。CSS不仅可以静态地修饰网页,还可以配合各种脚本语言动态地对网页各元素进行格式化。 |
|||
CSS 能够对网页中元素位置的排版进行像素级精确控制,支持几乎所有的字体字号样式,拥有对网页对象和模型样式编辑的能力。 |
|||
|
|||
> JavaScript |
|||
|
|||
JavaScript一种直译式脚本语言,是一种动态类型、弱类型、基于原型的语言,内置支持类型。它的解释器被称为JavaScript引擎,为浏览器的一部分,广泛用于客户端的脚本语言,最早是在HTML(标准通用标记语言下的一个应用)网页上使用,用来给HTML网页增加动态功能。 |
|||
|
|||
## 1.2、发展历史 |
|||
|
|||
### 静态页面阶段 |
|||
|
|||
互联网发展的早期,网站的前后端开发是一体的,即前端代码是后端代码的一部分。 |
|||
1.后端收到浏览器的请求 |
|||
2.生成静态页面 |
|||
3.发送到浏览器 |
|||
|
|||
那时的前端页面都是静态的,所有前端代码和前端数据都是后端生成的。前端只是纯粹的展示功能,脚本的作用只是增加一些特殊效果,比如那时很流行用脚本控制页面上飞来飞去的广告。 |
|||
|
|||
那时的网站开发,采用的是后端 MVC 模式。 |
|||
|
|||
* Model(模型层):提供/保存数据 |
|||
* Controller(控制层):数据处理,实现业务逻辑 |
|||
* View(视图层):展示数据,提供用户界面 |
|||
|
|||
前端只是后端 MVC 的 V。 |
|||
|
|||
### AJAX 阶段 |
|||
|
|||
2004年,AJAX 技术诞生,改变了前端开发。Gmail 和 Google 地图这样革命性的产品出现,使得开发者发现,前端的作用不仅仅是展示页面,还可以管理数据并与用户互动。 |
|||
|
|||
AJAX 技术指的是脚本独立向服务器请求数据,拿到数据以后,进行处理并更新网页。整个过程中,后端只是负责提供数据,其他事情都由前端处理。前端不再是后端的模板,而是实现了从“获取数据 --》 处理数据 --》展示数据”的完整业务逻辑。 |
|||
|
|||
就是从这个阶段开始,前端脚本开始变得复杂,不再仅仅是一些玩具性的功能。 |
|||
|
|||
### Web 2.0 |
|||
|
|||
Ajax技术促成了 Web 2.0 的诞生。 |
|||
Web 1.0:静态网页,纯内容展示 |
|||
Web 2.0:动态网页,富交互,前端数据处理 |
|||
|
|||
至此,前端早期的发展史就介绍完了,当时对于前端的要求并不高,只要掌握html css js和一个jquery就足够开发网页了 |
|||
|
|||
### 新时代的前端 |
|||
|
|||
到目前为止 HTML已经发展到HTML5 |
|||
CSS已经发展到CSS3.0 |
|||
JavaScript已经发展到ES9,但是常用的还是ES5和ES6 |
|||
现代标准浏览器(遵循W3C标准的浏览器)基本已经支持HTML5 CSS3 ES6的大部分特性 |
|||
|
|||
### 前端 MVC 阶段 |
|||
|
|||
前端代码有了读写数据、处理数据、生成视图等功能,因此迫切需要辅助工具,方便开发者组织代码。这导致了前端 MVC 框架的诞生。 |
|||
|
|||
2010年,第一个前端 MVC 框架 Backbone.js 诞生。它基本上是把 MVC 模式搬到了前端,但是只有 M (读写数据)和 V(展示数据),没有 C(处理数据)。因为,Backbone 认为前端 Controller 与后端不同,不需要、也不应该处理业务逻辑,只需要处理 UI 逻辑,响应用户的一举一动。所以,数据处理都放在后端,前端只用事件响应处理 UI 逻辑(用户操作)。 |
|||
|
|||
后来,更多的前端 MVC 框架出现。另一些框架提出 MVVM 模式,用 View Model 代替 Controller。MVVM 模式也将前端应用分成三个部分。 |
|||
|
|||
* Model:读写数据 |
|||
* View:展示数据 |
|||
* View-Model:数据处理 |
|||
|
|||
View Model 是简化的 Controller,所有的数据逻辑都放在这个部分。它的唯一作用就是为 View 提供处理好的数据,不含其他逻辑。也就是说,Model 拿到数据以后,View Model 将数据处理成视图层(View)需要的格式,在视图层展示出来。 |
|||
|
|||
这个模型的特点是 View 绑定 View Model。如果 View Model 的数据变了,View(视图层)也跟着变了;反之亦然,如果用户在视图层修改了数据,也立刻反映在 View Model。整个过程完全不需要手工处理。 |
|||
|
|||
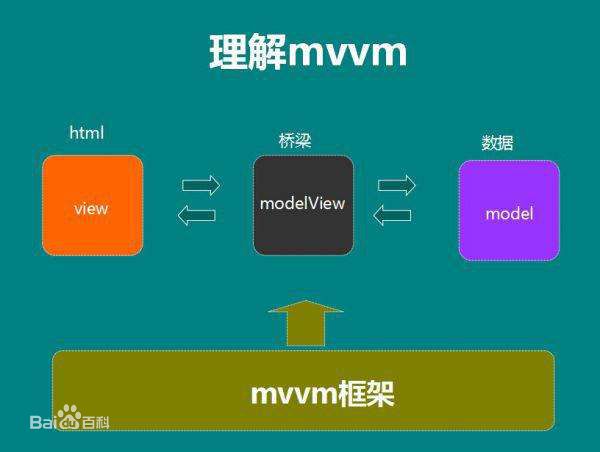
## 1.3、MVVM |
|||
|
|||
MVVM最早由微软提出来,它借鉴了桌面应用程序的MVC思想,在前端页面中,把Model用纯JavaScript对象表示,View负责显示,两者做到了最大限度的分离 把Model和View关联起来的就是ViewModel。 |
|||
ViewModel负责把Model的数据同步到View显示出来,还负责把View的修改同步回Model |
|||
View 和 Model 之间的同步工作完全是自动的,无需人为干涉 |
|||
因此开发者只需关注业务逻辑,不需要手动操作DOM, 不需要关注数据状态的同步问题,复杂的数据状态维护完全由 MVVM 来统一管理 |
|||
|
|||
 |
|||
|
|||
|
|||
|
|||
一个MVVM框架和jQuery操作DOM相比有什么区别? 我们先看用jQuery实现的修改两个DOM节点的例子: |
|||
|
|||
```text |
|||
<!-- HTML --> |
|||
<p>Hello, <span id="name">Bart</span>!</p> |
|||
<p>You are <span id="age">12</span>.</p> |
|||
|
|||
Hello, Bart! |
|||
|
|||
You are 12. |
|||
``` |
|||
|
|||
用jQuery修改name和age节点的内容: |
|||
|
|||
```text |
|||
var name = 'Homer'; |
|||
var age = 51; |
|||
|
|||
$('#name').text(name); |
|||
$('#age').text(age); |
|||
``` |
|||
|
|||
如果我们使用MVVM框架来实现同样的功能,我们首先并不关心DOM的结构,而是关心数据如何存储。最简单的数据存储方式是使用JavaScript对象: |
|||
|
|||
```text |
|||
var person = { |
|||
name: 'Bart', |
|||
age: 12 |
|||
} |
|||
``` |
|||
|
|||
我们把变量person看作Model,把HTML某些DOM节点看作View,并假定它们之间被关联起来了。 |
|||
|
|||
要把显示的name从Bart改为Homer,把显示的age从12改为51,我们并不操作DOM,而是直接修改JavaScript对象: |
|||
|
|||
```text |
|||
person.name = 'Homer'; |
|||
person.age = 51; |
|||
``` |
|||
|
|||
执行上面的代码,我们惊讶地发现,改变JavaScript对象的状态,会导致DOM结构作出对应的变化!这让我们的关注点从如何操作DOM变成了如何更新JavaScript对象的状态,而操作JavaScript对象比DOM简单多了! |
|||
|
|||
这就是MVVM的设计思想:关注Model的变化,让MVVM框架去自动更新DOM的状态,从而把开发者从操作DOM的繁琐步骤中解脱出来! |
|||
|
|||
|
|||
|
|||
 |
|||
|
|||
### 三大MVVM框架 |
|||
|
|||
* Vue |
|||
* React |
|||
* Angular |
|||
|
|||
> Vue |
|||
|
|||
Vue框架诞生于2014年,其作者为中国人——尤雨溪,也是新人最容易入手的框架之一,不同于React和Angular,其中文文档也便于大家阅读和学习。 |
|||
|
|||
> React |
|||
|
|||
React起源于Facebook的内部项目,因为该公司对市场上所有JavaScript MVC框架,都不满意,就决定自己写一套,用来架设Instagram的网站。做出来以后,发现这套东西很好用,就在2013年5月开源了。 |
|||
|
|||
> Angular |
|||
|
|||
Angular是谷歌开发的 Web 框架,具有优越的性能和绝佳的跨平台性。通常结合TypeScript开发,也可以使用JavaScript或Dart,提供了无缝升级的过渡方案。于2016年9月正式发布。 |
|||
|
|||
目前国内使用人数最多、最火的框架是Vue |
|||
|
|||
### webpack |
|||
|
|||
如今对于每一个前端工程师来说,webpack已经成为了一项基础技能,它基本上包办了本地开发、编译压缩、性能优化的所有工作。 |
|||
它的诞生意味着一整套工程化体系开始普及,并且让前端开发彻底告别了以前刀耕火种的时代。现在webpack之于前端开发,正如同gcc/g++之于C/C++,是一个无论如何都绕不开的工具。 |
|||
|
|||
### TypeScript(TS) |
|||
|
|||
TypeScript 是 Microsoft 开发和维护的一种面向对象的编程语言。它是JavaScript的超集,包含了JavaScript的所有元素,可以载入JavaScript代码运行,并扩展了JavaScript的语法。 TypeScript 具有以下特点: |
|||
|
|||
* TypeScript是Microsoft推出的开源语言,使用Apache授权协议 |
|||
* TypeScript增加了静态类型、类、模块、接口和类型注解 |
|||
|
|||
在开发大型项目时使用TS更有优势 |
|||
|
|||
### NodeJs |
|||
|
|||
Node.js是一个Javascript运行环境(runtime environment),发布于2009年5月,由Ryan Dahl开发,实质是对Chrome V8引擎进行了封装。Node.js对一些特殊用例进行优化,提供替代的API,使得V8在非浏览器环境下运行得更好。严格的来说,Node.js其实是一个后端语言。 |
|||
|
|||
特点: *单线程* 非阻塞IO *事件驱动* V8引擎 |
|||
|
|||
## 1.4、现在的前端能做什么? |
|||
|
|||
* 游戏开发(Egret Layabox coco2d-js) |
|||
* web开发(pc 移动端设备) |
|||
* webApp开发(Dcloud RN weex ionic) |
|||
* 图形开发WebGl(three.js) |
|||
* 小程序/快应用 |
|||
* 后端(nodejs) |
|||
* 桌面应用(electron) |
|||
* 嵌入式开发(Ruff) |
|||
|
|||
## 1.5、前端的未来 |
|||
|
|||
现在基于Web的前端技术,将演变为未来所有软件的通用的GUI解决方案。 所以前端有可能会变成一名端工程师。 *PC端* 手机端 *TV端* VR端 |
|||
|
|||
...... |
|||
|
|||
## 1.6、一名合格的前端需要掌握哪些技能 |
|||
|
|||
* photoshop切图(必修) |
|||
* html css js(特别是html5 css3 es6)(必修) |
|||
* 三大前端框架至少精通一个(必修) |
|||
* nodejs(选修) |
|||
* 自动化构建工具webpack(必修) |
|||
* http协议(必修) |
|||
* 浏览器渲染流程及原理(必修) |
|||
* TypeScript(选修) |
|||
|
|||
## 2、 |
|||
@ -0,0 +1,775 @@ |
|||
--- |
|||
title: javaIO流 |
|||
author: TianZD |
|||
top: true |
|||
cover: true |
|||
toc: true |
|||
mathjax: false |
|||
summary: java io流学习笔记,粗略学了一下,没有参考价值 |
|||
tags: |
|||
- IO |
|||
- 学习笔记 |
|||
- Java |
|||
categories: |
|||
- java |
|||
reprintPolicy: cc_by |
|||
abbrlink: 47e3b155 |
|||
date: 2022-04-29 11:03:06 |
|||
coverImg: |
|||
img: |
|||
password: |
|||
--- |
|||
|
|||
|
|||
[TOC] |
|||
|
|||
# IO |
|||
|
|||
# 数据源 |
|||
|
|||
数据源Data Source,提供数据的原始媒介,如:数据库、文件、其他程序、内存、网络连接、IO设备等; |
|||
|
|||
数据源分为:源设备、目标设备 |
|||
|
|||
1. 源设备:为程序提供数据,一般对应输入流 |
|||
2. 目标设备:程序数据的目的地,一般对应输出流 |
|||
|
|||
# 流 |
|||
|
|||
流是一个抽象、动态的概念,是一连串连续动态的数据集合。 |
|||
|
|||
流:字节流、字符流 |
|||
|
|||
# 四大IO抽象类 |
|||
|
|||
InputStream/OutputStream是字节的输入输出流抽象父类 |
|||
|
|||
Reader/Writer是字符的IO流抽象父类 |
|||
|
|||
# InputStream |
|||
|
|||
> 字节输入流的所有类的父类。根据节点的不同,派生了不同的节点流子类,数据的单位为字节byte(8bite)。 |
|||
|
|||
1. int read():读取一个字节的数据,并作为int类型返回(0-255),如果未读出,则返回-1,返回-1表示读取结束; |
|||
2. void close():关闭输入流对象,释放相关系统资源,用完一定要关闭。 |
|||
|
|||
# OutputStream |
|||
|
|||
>表示字节输出流的所有类的父类,接受输出字节并发送到某个目的地; |
|||
|
|||
1. void write(int n):向某个目的地写入一个字节; |
|||
2. void close():关闭输出流对象,释放相关系统资源。 |
|||
|
|||
# Reader |
|||
|
|||
>读取字符流的抽象类,数据单位为字符 |
|||
|
|||
1. int read():读取一个字符数据,作为int类型返回(0-65535之间的一个unicode值),如果未读出,则返回-1,返回-1表示读取结束; |
|||
2. void close():关闭输入流对象,释放相关系统资源,用完一定要关闭。 |
|||
|
|||
# Writer |
|||
|
|||
>用于输出的字符流抽象类,数据单位为字符 |
|||
|
|||
1. void write(int n):向某个目的地写入一个字符; |
|||
2. void close():关闭输出流对象,释放相关系统资源。 |
|||
|
|||
# 流的概念细分 |
|||
|
|||
按流的方向: |
|||
|
|||
1. 输入流,以InputStream、Reader结尾的流 |
|||
2. 输出流,以OutputStream、Writer结尾的流 |
|||
|
|||
按处理的数据单元: |
|||
|
|||
1. 字节流:以字节为单位获取数据,一般命名上以Stream为结尾的流为字节流; |
|||
2. 字符流:以字符为单位获取数据,一般以Reader/Writer结尾的流 |
|||
|
|||
按处理对象不同: |
|||
|
|||
1. 节点流:可以直接从数据源或者目的地读写数据 |
|||
2. 处理流:不直接连接到数据源或者目的地,是“处理流的流”,通过对其他流的处理提高程序的性能,也叫包装流; |
|||
|
|||
节点流处于IO操作的第一线,所有操作都必须通过他们进行;处理流可以对节点流进行包装,提高性能或者提高程序的灵活性 |
|||
|
|||
# IO流体系 |
|||
|
|||
1. InputStream/OutputStream:字节流的抽象类 |
|||
2. Reader/Writer:字符流的抽象类 |
|||
3. FileInputStream/FileOutputStream:节点流,以字节为单位直接操作”文件“ |
|||
4. ByteArrayIuputStream/ByteArrayOutputStream:节点流,以字节为单位直接操作”字节数组对象“ |
|||
5. ObjectInputStream/ObjectOutputStream:处理流,以字节为单位直接操作”对象“ |
|||
6. DataInputStream/DataOutputStream:处理流,以字节为单位直接操作”基本数据类型与字符串类型“ |
|||
7. FileReader/FileWriter:节点流,以字符为单位直接操作”文本文件“,注意,只能读写文本文件 |
|||
8. BufferedReader/BufferedWriter:处理流,将Reader/Writer对象进行包装,增加缓存功能,提高读写效率 |
|||
9. BufferedInputStream/BufferedOutputStream:处理流,将InputStream/OutputStream对象进行包装,增加缓存功能,提高读写效率 |
|||
10. InputStreamReader/OutputStreamWriter:处理流,将字节流对象转化成字符流对象 |
|||
11. PrintStream:处理流,将OutputStream进行包装,可以方便输出字符,更加灵活 |
|||
|
|||
# IO流第一个例子 |
|||
|
|||
```java |
|||
import java.io.FileInputStream; |
|||
import java.io.FileNotFoundException; |
|||
import java.io.IOException; |
|||
/** |
|||
* 读取E:\a.txt文件中的”tianzhendong“ |
|||
*/ |
|||
public class Test1 { |
|||
public static void main(String[] args) { |
|||
//实例化IO输入流对象 |
|||
FileInputStream fis1 = null; |
|||
StringBuilder sb = new StringBuilder( ); |
|||
try { |
|||
fis1 = new FileInputStream("e:/a.txt"); |
|||
int temp = 0; |
|||
while ((temp = (fis1.read())) != -1){ //read()每次读取一个字符,并返回int型的ASCII值 |
|||
System.out.println(temp); //输出对应的ASCII |
|||
sb.append((char)temp); |
|||
} |
|||
System.out.println(sb.toString()); |
|||
} catch (Exception e) { |
|||
e.printStackTrace(); |
|||
} finally { |
|||
if(fis1 != null){ |
|||
try { |
|||
fis1.close(); |
|||
} catch (IOException e) { |
|||
e.printStackTrace(); |
|||
} |
|||
} |
|||
} |
|||
} |
|||
} |
|||
|
|||
``` |
|||
|
|||
# File类 |
|||
|
|||
通过file类操作文件 |
|||
|
|||
```java |
|||
import java.io.File; |
|||
import java.io.IOException; |
|||
|
|||
public class FileDemo { |
|||
public static void main(String[] args) throws IOException { |
|||
//实例化File对象 |
|||
File file = new File("e:/b.txt"); |
|||
System.out.println(file.createNewFile()); |
|||
//查看对象是否存在 |
|||
System.out.println(file.exists()); |
|||
//查看对象是否是隐藏文件 |
|||
System.out.println(file.isHidden()); |
|||
//查看绝对路径 |
|||
System.out.println(file.getAbsoluteFile()); |
|||
//查看相对路径 |
|||
System.out.println(file.getPath()); |
|||
//查看名字 |
|||
System.out.println(file.getName()); |
|||
//查看路径加名字 |
|||
System.out.println(file); |
|||
//查看长度 |
|||
System.out.println(file.length()); |
|||
//删除文件 |
|||
System.out.println(file.delete()); |
|||
} |
|||
} |
|||
/** |
|||
true |
|||
true |
|||
false |
|||
e:\b.txt |
|||
e:\b.txt |
|||
b.txt |
|||
e:\b.txt |
|||
0 |
|||
true |
|||
*/ |
|||
``` |
|||
|
|||
## 通过file操作目录 |
|||
|
|||
```java |
|||
import java.io.File; |
|||
import java.io.IOException; |
|||
|
|||
public class DirectoryDeom { |
|||
public static void main(String[] args) throws IOException { |
|||
//实例化对象,mkdirs可以创建多级目录 |
|||
File file = new File("e:/test"); |
|||
System.out.println(file.mkdir()); |
|||
//判断是否是目录 |
|||
System.out.println(file.isDirectory()); |
|||
//获取父级目录 |
|||
System.out.println(file.getParentFile()); |
|||
//查看包含的文件和目录的路径名 |
|||
File file1 = new File("e:/"); |
|||
String [] list = file1.list(); |
|||
for(String s :list){ |
|||
System.out.println(s); |
|||
} |
|||
//返回一个file数组,表示目录中的文件的绝对路径,和list不同的是,文件名带路径 |
|||
File[] files = file1.listFiles(); |
|||
for(File f : files){ |
|||
System.out.println(f);; |
|||
} |
|||
} |
|||
} |
|||
|
|||
``` |
|||
|
|||
# 文件字节流 |
|||
|
|||
* FileInputStream通过字节的方式读取文件,适合读取所有类型的文件(图像、视频、文本文件等)。Java也提供了FileReader专门读取文件文件; |
|||
* FileOutputStream通过字节的方式写数据到文件中,适合所有类型的文件。java也提供了FileWriter专门写入文本文件。 |
|||
|
|||
## 例子 |
|||
|
|||
```java |
|||
package com.IO; |
|||
|
|||
import java.io.FileInputStream; |
|||
import java.io.FileOutputStream; |
|||
import java.io.IOException; |
|||
|
|||
public class FileStreamDemo { |
|||
public static void main(String[] args) throws IOException { |
|||
//程序开始时间 |
|||
long start = System.currentTimeMillis(); |
|||
|
|||
FileInputStream fis = null; |
|||
FileOutputStream fos = null; |
|||
try { |
|||
//实例化 |
|||
fis = new FileInputStream("e:/灵笼.png"); |
|||
fos = new FileOutputStream("e:/灵笼2.png"); |
|||
int temp = 0; |
|||
while ((temp = fis.read())!=-1){ |
|||
//输出 |
|||
//System.out.println(temp); |
|||
//复制到fos |
|||
fos.write(temp); |
|||
} |
|||
//将数据从内存写入到磁盘 |
|||
fos.flush(); |
|||
} catch (Exception e){ |
|||
e.printStackTrace(); |
|||
} finally { |
|||
//关闭fis和fos |
|||
if(fis != null){ |
|||
fis.close(); |
|||
} |
|||
if(fos != null){ |
|||
fos.close(); |
|||
} |
|||
} |
|||
//程序结束时间 |
|||
long end = System.currentTimeMillis(); |
|||
System.out.println("运行时间为:"+ (end - start)+"ms"); |
|||
} |
|||
} |
|||
/* |
|||
*运行时间为:102ms |
|||
*/ |
|||
``` |
|||
|
|||
## 通过缓冲区提高读写效率 |
|||
|
|||
### 方式一 |
|||
|
|||
通过创建一个指定长度的字节数组作为缓冲区,以此来提高IO流的读写效率。该方式适合读取较大图片时的缓冲区定义。注意:缓冲区的长度一定是2的整数幂。一般情况下,**1024**长度较为合适 |
|||
|
|||
```java |
|||
package com.IO; |
|||
|
|||
import java.io.FileInputStream; |
|||
import java.io.FileOutputStream; |
|||
import java.io.IOException; |
|||
|
|||
public class FileStreamBuffDemo { |
|||
public static void main(String[] args) throws IOException { |
|||
//程序开始时间 |
|||
long start = System.currentTimeMillis(); |
|||
|
|||
FileInputStream fis = null; |
|||
FileOutputStream fos = null; |
|||
try { |
|||
//实例化 |
|||
fis = new FileInputStream("e:/灵笼.png"); |
|||
fos = new FileOutputStream("e:/灵笼2.png"); |
|||
int temp = 0; |
|||
//创建一个缓冲区,提高读写效率 |
|||
byte[] buff = new byte[1024]; |
|||
|
|||
while ((temp = fis.read(buff))!=-1){ |
|||
//输出 |
|||
//System.out.println(temp); |
|||
//复制到fos |
|||
fos.write(buff,0, temp); |
|||
} |
|||
//将数据从内存写入到磁盘 |
|||
fos.flush(); |
|||
} catch (Exception e){ |
|||
e.printStackTrace(); |
|||
} finally { |
|||
//关闭fis和fos |
|||
if(fis != null){ |
|||
fis.close(); |
|||
} |
|||
if(fos != null){ |
|||
fos.close(); |
|||
} |
|||
} |
|||
//程序结束时间 |
|||
long end = System.currentTimeMillis(); |
|||
System.out.println("运行时间为:"+ (end - start)+"ms"); |
|||
} |
|||
} |
|||
/* |
|||
*运行时间为:13ms |
|||
*/ |
|||
``` |
|||
|
|||
### 方式二 |
|||
|
|||
也是通过创建一个字节数组作为缓冲区,但是长度直接通过available()返回当前文件的预估长度,通过一次读写操作中完成。注意,文件过大时,占用的内存较大。大文件不推荐; |
|||
|
|||
```java |
|||
package com.IO; |
|||
|
|||
import java.io.FileInputStream; |
|||
import java.io.FileOutputStream; |
|||
import java.io.IOException; |
|||
|
|||
public class FileStreamBuff2Demo { |
|||
public static void main(String[] args) throws IOException { |
|||
//程序开始时间 |
|||
long start = System.currentTimeMillis(); |
|||
|
|||
FileInputStream fis = null; |
|||
FileOutputStream fos = null; |
|||
try { |
|||
//实例化 |
|||
fis = new FileInputStream("e:/灵笼.png"); |
|||
fos = new FileOutputStream("e:/灵笼2.png"); |
|||
|
|||
//创建一个缓冲区,提高读写效率 |
|||
byte[] buff = new byte[fis.available()]; |
|||
fis.read(buff); |
|||
//一次性复制,不需要循环 |
|||
fos.write(buff); |
|||
//将数据从内存写入到磁盘 |
|||
fos.flush(); |
|||
} catch (Exception e){ |
|||
e.printStackTrace(); |
|||
} finally { |
|||
//关闭fis和fos |
|||
if(fis != null){ |
|||
fis.close(); |
|||
} |
|||
if(fos != null){ |
|||
fos.close(); |
|||
} |
|||
} |
|||
//程序结束时间 |
|||
long end = System.currentTimeMillis(); |
|||
System.out.println("运行时间为:"+ (end - start)+"ms"); |
|||
} |
|||
} |
|||
``` |
|||
|
|||
## 通过字节缓冲流提高读取效率 |
|||
|
|||
>java缓冲流本身并不具有IO流的读写功能,只是在别的流上加上缓冲功能提高效率,因此缓冲流是一种处理流/包装流; |
|||
|
|||
当对文件或者其他数据源进行频繁的读写操作时,效率低,这是如果使用缓冲流可以提高效率;缓冲流是先将数据缓存起来,当缓存区满以后或者手动刷新时再一次性的读取到程序或写入目的地; |
|||
|
|||
BufferedInputStream和BufferedOutputStream这两个是缓冲字节流通过内部缓存数组来提高操作流的效率。 |
|||
|
|||
**缓冲区中,默认的byte数组长度为8192** |
|||
|
|||
|
|||
```java |
|||
import java.io.BufferedInputStream; |
|||
import java.io.BufferedOutputStream; |
|||
import java.io.FileInputStream; |
|||
import java.io.FileOutputStream; |
|||
|
|||
public class FileStreamBuffer3Demo { |
|||
public static void main(String[] args) { |
|||
long startTime = System.currentTimeMillis(); |
|||
FileInputStream fis = null; |
|||
BufferedInputStream bis = null; |
|||
FileOutputStream fos = null; |
|||
BufferedOutputStream bos = null; |
|||
try { |
|||
fis = new FileInputStream("e:/灵笼.png"); |
|||
bis = new BufferedInputStream(fis); |
|||
fos = new FileOutputStream("e:/灵笼11.png"); |
|||
bos = new BufferedOutputStream(fos); |
|||
int temp = 0; |
|||
while ((temp = bis.read())!= -1){ |
|||
bos.write(temp); |
|||
} |
|||
bos.flush(); |
|||
}catch (Exception e){ |
|||
e.printStackTrace(); |
|||
}finally { |
|||
try { |
|||
//关闭时,先关处理流/包装流 |
|||
bos.close(); |
|||
fos.close(); |
|||
bis.close(); |
|||
fis.close(); |
|||
}catch (Exception e){ |
|||
e.printStackTrace(); |
|||
} |
|||
} |
|||
long endTime = System.currentTimeMillis(); |
|||
System.out.println("运行时间:"+ (endTime - startTime)+"ms"); |
|||
} |
|||
} |
|||
``` |
|||
|
|||
# 转换流 |
|||
|
|||
InputStreamReader/OutputStreamWriter实现将字节流转化成字符流 |
|||
|
|||
## 通过转换流实现键盘输入到屏幕输出 |
|||
|
|||
```java |
|||
package com.IO; |
|||
|
|||
import java.io.*; |
|||
|
|||
public class ConvertStream { |
|||
public static void main(String[] args) { |
|||
//InputStream is = System.in; |
|||
BufferedReader bf = null; |
|||
BufferedWriter bw = null; |
|||
try { |
|||
//将字节流对象System.in转换为字符流对象,实现一次采集一行数据 |
|||
bf = new BufferedReader(new InputStreamReader(System.in)); |
|||
bw = new BufferedWriter(new OutputStreamWriter(System.out)); |
|||
while (true){ |
|||
bw.write("please input:"); |
|||
bw.flush(); |
|||
String input = bf.readLine(); |
|||
if(input.equals("exit")) |
|||
break; |
|||
//实现屏幕输出,等同于System.out.println(input); |
|||
bw.write("您输入的是:"+input); |
|||
bw.newLine(); |
|||
bw.flush(); |
|||
} |
|||
|
|||
} catch (IOException e) { |
|||
e.printStackTrace(); |
|||
} finally { |
|||
try { |
|||
bf.close(); |
|||
bw.close(); |
|||
} catch (IOException e) { |
|||
e.printStackTrace(); |
|||
} |
|||
} |
|||
|
|||
} |
|||
} |
|||
``` |
|||
|
|||
# 字符输出流 |
|||
|
|||
java中提供了用于字符输出的流对象PrintWriter,**具有自动行刷新缓冲字符输出流**,不需要在flush,特点是可以按行写出字符串,并可通过println()实现自动换行 |
|||
|
|||
# 字节数组流 |
|||
|
|||
ByteArrayInputStream和ByteArrayOutputStream经常用在需要流和数组之间转换的情况 |
|||
|
|||
## 字节数组输入流 |
|||
|
|||
FileInputStream把文件当作数据源;ByteArrayInputStream把内存中的“字节数组对象”当作数据源。 |
|||
|
|||
```java |
|||
package com.IO; |
|||
|
|||
import java.io.ByteArrayInputStream; |
|||
|
|||
public class ByteArrayInputStreamDemo { |
|||
public static void main(String[] args) { |
|||
//创建字节数组,作为数据源 |
|||
byte [] bytes = "tianzhendong".getBytes(); |
|||
|
|||
ByteArrayInputStream bais = null; |
|||
StringBuilder sb = new StringBuilder(); |
|||
try { |
|||
bais = new ByteArrayInputStream(bytes); |
|||
int temp = 0; |
|||
while ((temp = bais.read())!= -1){ |
|||
sb.append((char)temp); |
|||
} |
|||
System.out.println(sb.toString()); |
|||
} finally { |
|||
try { |
|||
bais.close(); |
|||
} catch (Exception e){ |
|||
e.printStackTrace(); |
|||
} |
|||
} |
|||
} |
|||
} |
|||
``` |
|||
|
|||
## 字节数组输出流 |
|||
|
|||
将流中的数据写入到字节数组中 |
|||
|
|||
```java |
|||
package com.IO; |
|||
|
|||
import java.io.ByteArrayOutputStream; |
|||
|
|||
public class ByteArrayOutputStreamDemo { |
|||
public static void main(String[] args) { |
|||
ByteArrayOutputStream bos = null; |
|||
try { |
|||
StringBuilder sb = new StringBuilder(); |
|||
bos = new ByteArrayOutputStream(); |
|||
//添加字符 |
|||
bos.write('t'); |
|||
bos.write('i'); |
|||
bos.write('a'); |
|||
bos.write('n'); |
|||
//获取字符数组 |
|||
byte [] arr = bos.toByteArray(); |
|||
//添加到字符串中 |
|||
for(int i : arr){ |
|||
sb.append((char) i); |
|||
} |
|||
System.out.println(sb.toString()); |
|||
} finally { |
|||
try { |
|||
bos.close(); |
|||
} catch (Exception e){ |
|||
e.printStackTrace(); |
|||
} |
|||
} |
|||
} |
|||
} |
|||
``` |
|||
|
|||
# 数据流 |
|||
|
|||
>数据流将基本数据类型与字符串类型作为数据源,从而允许程序以与机器无关的方式从底层输入输出流中操作java基本数据类型与字符串类型 |
|||
|
|||
DataInputStream和DataOutputStream提供了可以存取与机器无关的所有java基础类型的方法 |
|||
|
|||
```java |
|||
package com.IO; |
|||
|
|||
import java.io.*; |
|||
|
|||
public class DataIOStreamDemo { |
|||
public static void main(String[] args) { |
|||
DataInputStream dis = null; |
|||
DataOutputStream dos = null; |
|||
try { |
|||
dos = new DataOutputStream(new BufferedOutputStream(new FileOutputStream("e:/a.txt"))); |
|||
dis = new DataInputStream(new BufferedInputStream(new FileInputStream("e:/a.txt"))); |
|||
//写入 |
|||
dos.writeBoolean(true); //写入boolean类型 |
|||
dos.writeChar('t'); //写入char类型 |
|||
dos.writeInt(10); //写入int |
|||
dos.writeUTF("tian"); //写入string |
|||
dos.flush(); |
|||
//读取,顺序必须和写入一致 |
|||
System.out.println("boolean:"+dis.readBoolean()); |
|||
System.out.println("char:"+dis.readChar()); |
|||
System.out.println("int:"+dis.readInt()); |
|||
System.out.println("string:"+dis.readUTF()); |
|||
} catch (Exception e){ |
|||
e.printStackTrace(); |
|||
} finally { |
|||
try { |
|||
dis.close(); |
|||
dos.close(); |
|||
} catch (Exception e){ |
|||
e.printStackTrace(); |
|||
} |
|||
} |
|||
} |
|||
} |
|||
``` |
|||
|
|||
# 对象流 |
|||
|
|||
对象的本质可是用来组织和存储数据的,本身也是数据 |
|||
|
|||
## 序列化和反序列化 |
|||
|
|||
当两个进程远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送 |
|||
|
|||
当发送java对象时,发送方需要把java对象转化为字节序列,接收方需要把字节序列恢复为java对象,成为序列化和反序列化 |
|||
|
|||
对象序列化的作用 |
|||
|
|||
1. 持久性:把对象的字节序列永久地保存到硬盘上,通常存放到一个文件中 |
|||
2. 网络通信:在网络上传送对象的字节序列,如:服务器之间的数据通信、对象传递 |
|||
|
|||
### 序列化设计的类和接口 |
|||
|
|||
ObjectOutputStream代表对象输出流,他的writeObject()方法可将对象进行序列化,把得到的字节序列写到一个目标输出流中 |
|||
|
|||
ObjectInputStream代表对象输入流,readObject()方法从一个源输入流中读取字节序列,再把他们反序列化为一个对象,并返回 |
|||
|
|||
注:**只有实现了Serializable接口的类的对象才能被序列化,Serializable接口是一个空接口,只起到标记作用** |
|||
|
|||
|
|||
## 操作基本数据类型 |
|||
|
|||
对象流中不仅可以实现对基本数据类型进行读写操作,还能对java对象进行读写操作 |
|||
|
|||
读写基本数据类型时用法同DataInputStream和DataOutputStream |
|||
|
|||
## 操作对象 |
|||
|
|||
将内存中的java对象通过序列化的方式写入磁盘的文件中,被序列化的对象必须要实现serializable序列化接口,复制会抛出异常 |
|||
|
|||
### 创建对象 |
|||
|
|||
```java |
|||
package com.IO; |
|||
|
|||
import java.io.Serializable; |
|||
|
|||
public class Users implements Serializable { |
|||
private int userid; |
|||
private String username; |
|||
private int userage; |
|||
|
|||
public Users(int userid, String username, int userage) { |
|||
this.userid = userid; |
|||
this.username = username; |
|||
this.userage = userage; |
|||
} |
|||
|
|||
public Users() { |
|||
} |
|||
|
|||
public int getUserid() { |
|||
return userid; |
|||
} |
|||
|
|||
public void setUserid(int userid) { |
|||
this.userid = userid; |
|||
} |
|||
|
|||
public String getUsername() { |
|||
return username; |
|||
} |
|||
|
|||
public void setUsername(String username) { |
|||
this.username = username; |
|||
} |
|||
|
|||
public int getUserage() { |
|||
return userage; |
|||
} |
|||
|
|||
public void setUserage(int userage) { |
|||
this.userage = userage; |
|||
} |
|||
} |
|||
``` |
|||
|
|||
### 序列化对象 |
|||
|
|||
```java |
|||
package com.IO; |
|||
|
|||
import java.io.FileOutputStream; |
|||
import java.io.ObjectOutputStream; |
|||
|
|||
public class ObjectOutputStreamDemo { |
|||
public static void main(String[] args) { |
|||
ObjectOutputStream oos = null; |
|||
try { |
|||
oos = new ObjectOutputStream(new FileOutputStream("e:/b")); |
|||
Users u = new Users(1,"tianzhendong",21); |
|||
oos.writeObject(u); |
|||
oos.flush(); |
|||
} catch (Exception e){ |
|||
e.printStackTrace(); |
|||
} finally { |
|||
try { |
|||
if(oos!=null){ |
|||
oos.close(); |
|||
} |
|||
}catch (Exception e){ |
|||
e.printStackTrace(); |
|||
} |
|||
} |
|||
} |
|||
} |
|||
``` |
|||
|
|||
### 反序列化对象 |
|||
|
|||
```java |
|||
package com.IO; |
|||
|
|||
import java.io.FileInputStream; |
|||
import java.io.ObjectInputStream; |
|||
|
|||
public class ObjectInputStreamDemo { |
|||
public static void main(String[] args) { |
|||
ObjectInputStream ois = null; |
|||
try { |
|||
ois = new ObjectInputStream(new FileInputStream("e:/b")); |
|||
Users u1 = (Users) ois.readObject(); |
|||
System.out.println(u1.getUserid()+"\t"+u1.getUsername()+"\t"+u1.getUserage()); |
|||
} catch (Exception e){ |
|||
e.printStackTrace(); |
|||
} finally { |
|||
try { |
|||
if(ois != null){ |
|||
ois.close(); |
|||
} |
|||
}catch (Exception e){ |
|||
e.printStackTrace(); |
|||
} |
|||
} |
|||
} |
|||
} |
|||
``` |
|||
|
|||
# 随机访问流 |
|||
|
|||
RandomAccessFile作用: |
|||
|
|||
1. 实现对一个文件做读和写的操作 |
|||
2. 可以访问文件的任意位置,不像其他流只能按照先后顺序读取 |
|||
|
|||
在开发客户端软件时,经常用到 |
|||
|
|||
核心方法: |
|||
|
|||
1. RandomAccessFile(String name , String mode);name 用来确定文件;mode取r只读或者rw读写,通过mode确定流对文件的访问权限 |
|||
2. seek(long a ),用来定位流对象读写文件的位置,a确定读写位置距离文件开头的字节个数 |
|||
3. 个体FilePointer()获得流的当前读写位置 |
|||
|
|||
# File类在IO中的作用 |
|||
|
|||
当以文件作为数据源或者目标时,除了可以使用字符串作为文件以及位置的指定以外,也可以使用File类指定 |
|||
|
|||
# Apache IO包 |
|||
|
|||
Apache-commons工具包中提供了IOUtils/FileUtils,可以方便的对文件和目录进行操作。 |
|||
|
|||
## 下载和添加commons包 |
|||
|
|||
https://commons.apache.org/proper/commons-io/download_io.cgi |
|||
|
|||
下载后在项目设置、libraries中添加 |
|||
@ -0,0 +1,105 @@ |
|||
--- |
|||
title: java一些知识点 |
|||
author: TianZD |
|||
top: true |
|||
cover: true |
|||
toc: true |
|||
mathjax: false |
|||
summary: java学习中的一些知识点记录,粗略学了一下,没有参考价值 |
|||
tags: |
|||
- java |
|||
- 学习笔记 |
|||
categories: |
|||
- java |
|||
reprintPolicy: cc_by |
|||
abbrlink: 89d8704 |
|||
date: 2022-04-29 11:04:44 |
|||
coverImg: |
|||
img: |
|||
password: |
|||
--- |
|||
|
|||
|
|||
|
|||
[toc] |
|||
|
|||
# java中int值2147483647+2=-2147483647 |
|||
|
|||
nt的取值范围为:-231——231-1,即-2147483648——2147483647 |
|||
因为一个数据类型的最大值和最小值是一个循环,也就是说在最大值的基础上再扩大数值或者在最小值的基础上再缩小数值,会跳到相反的最值上面。 |
|||
|
|||
# 重载和重写 |
|||
|
|||
重写(Override)是父类与子类之间多态性的一种表现。如果在子类中定义某方法与其父类有相同的名称和参数,我们说该方法被重写 (Override)。 |
|||
|
|||
重载(Overload)是一个类中多态性的一种表现。如果在一个类中定义了多个同名的方法,它们参数列表不同,则称为方法的重载(Overload) |
|||
|
|||
区别:重载实现于一个类中;重写实现于子类中。 |
|||
|
|||
重载(Overload):是**一个类中多态性**的一种表现,指同一个类中不同的函数使用**相同的函数名**,但是**函数的参数个数或类型不同**。**可以有不同的返回类型**;可以有不同的访问修饰符;可以抛出不同的异常。调用的时候**根据函数的参数来区别不同的函数**。 |
|||
|
|||
重写(Override): 是父**类与子类之间的多态性**,是子类对父类函数的重新实现。函数名和参数与父类一样,子类与父类**函数体内容不一样**。子类**返回的类型必须与父类保持一致**;子类方法**访问修饰符的限制一定要大于父类**方法的访问修饰(public>protected>default>private);子类重写方法一定不能抛出新的检查异常或者比被父类方法申明更加宽泛的检查型异常。 |
|||
|
|||
# 一个java文件中多个类 |
|||
|
|||
一个.java文件中可以有很多类。不过注意以下几点: |
|||
|
|||
* public 权限的类只能有一个(也可以一个都没有,但最多只有1个) |
|||
* 这个.java文件的文件名必须是public类的类名(一般的情况下,这里放置main方法是程序的入口。) |
|||
* 若这个文件中没有public的类,则文件名随便是一个类的名字即可 |
|||
* 用javac 编译这个.java文件的时候,它会给每一个类生成一个.class文件 |
|||
|
|||
# Java中DAO层、Service层和Controller层的区别 |
|||
|
|||
DAO层: |
|||
DAO层叫数据访问层,全称为data access object,属于一种比较底层,比较基础的操作,具体到对于某个表的增删改查,也就是说某个DAO一定是和数据库的某一张表一一对应的,其中封装了增删改查基本操作,建议DAO只做原子操作,增删改查。 |
|||
|
|||
Service层: |
|||
Service层叫服务层,被称为服务,粗略的理解就是对一个或多个DAO进行的再次封装,封装成一个服务,所以这里也就不会是一个原子操作了,需要事物控制。 |
|||
|
|||
Controler层: |
|||
Controler负责请求转发,接受页面过来的参数,传给Service处理,接到返回值,再传给页面。 |
|||
|
|||
总结: |
|||
个人理解DAO面向表,Service面向业务。后端开发时先数据库设计出所有表,然后对每一张表设计出DAO层,然后根据具体的业务逻辑进一步封装DAO层成一个Service层,对外提供成一个服务。 |
|||
|
|||
SSM是sping+springMVC+mybatis集成的框架。 |
|||
|
|||
MVC即model view controller。 |
|||
|
|||
model层=entity层。存放我们的实体类,与数据库中的属性值基本保持一致。 |
|||
|
|||
service层。存放业务逻辑处理,也是一些关于数据库处理的操作,但不是直接和数据库打交道,他有接口还有接口的实现方法,在接口的实现方法中需要导入mapper层,mapper层是直接跟数据库打交道的,他也是个接口,只有方法名字,具体实现在mapper.xml文件里,service是供我们使用的方法。 |
|||
|
|||
mapper层=dao层,现在用mybatis逆向工程生成的mapper层,其实就是dao层。对数据库进行数据持久化操作,他的方法语句是直接针对数据库操作的,而service层是针对我们controller,也就是针对我们使用者。service的impl是把mapper和service进行整合的文件。 |
|||
|
|||
(多说一句,数据持久化操作就是指,把数据放到持久化的介质中,同时提供增删改查操作,比如数据通过hibernate插入到数据库中。) |
|||
|
|||
controller层。控制器,导入service层,因为service中的方法是我们使用到的,controller通过接收前端传过来的参数进行业务操作,在返回一个指定的路径或者数据表。 |
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
**1、dao层** |
|||
|
|||
dao层主要做数据持久层的工作, 负责与数据库进行联络的一些任务都封装在此 ,dao层的设计 首先 是设计dao层的接口,然后在Spring的配置文件中定义此接口的实现类,然后就可以再模块中调用此接口来进行数据业务的处理,而不用关心此接口的具体实现类是哪个类,显得结构非常清晰,dao层的数据源配置,以及有关数据库连接参数都在Spring配置文件中进行配置。 |
|||
|
|||
**2、service层** |
|||
|
|||
service层主要负责业务模块的应用逻辑应用设计。同样是 首先设计接口 , 再设计其实现类 ,接着再Spring的配置文件中配置其实现的关联。这样我们就可以在应用中调用service接口来进行业务处理。service层的业务实, 具体要调用已经定义的dao层接口 ,封装service层业务逻辑有利于通用的业务逻辑的独立性和重复利用性。程序显得非常简洁。 |
|||
|
|||
**3、controller层** |
|||
|
|||
controller层 负责具体的业务模块流程的控制 ,在此层要 调用service层的接口来控制业务流程 ,控制的配置也同样是在Spring的配置文件里进行,针对具体的业务流程,会有不同的控制器。我们具体的设计过程可以将流程进行抽象归纳,设计出可以重复利用的子单元流程模块。 这样不仅使程序结构变得清晰,也大大减少了代码量。 |
|||
|
|||
**4、view层** |
|||
|
|||
view层与控制层结合比较紧密,需要二者结合起来协同开发。view层主要负责前台jsp页面的显示。 |
|||
|
|||
|
|||
|
|||
**5、它们之间的关系:** |
|||
|
|||
Service层是建立在DAO层之上的,建立了DAO层后才可以建立Service层,而Service层又是在Controller层之下的,因而 Service层应该既调用DAO层的接口,又要提供接口给Controller层的类来进行调用,它刚好处于一个中间层的位置。 每个模型都有一个Service接口,每个接口分别封装各自的业务处理方法。 |
|||
File diff suppressed because it is too large
@ -0,0 +1,736 @@ |
|||
--- |
|||
title: java容器 |
|||
author: TianZD |
|||
top: true |
|||
cover: true |
|||
toc: true |
|||
mathjax: false |
|||
summary: java容器学习笔记,粗略学了一下,没有参考价值 |
|||
tags: |
|||
- java |
|||
- 容器 |
|||
- 学习笔记 |
|||
categories: |
|||
- java |
|||
reprintPolicy: cc_by |
|||
abbrlink: 17ea147a |
|||
date: 2022-04-29 11:00:40 |
|||
coverImg: |
|||
img: |
|||
password: |
|||
--- |
|||
|
|||
|
|||
|
|||
[TOC] |
|||
|
|||
# 泛型 |
|||
|
|||
JDK1.5(即5.0)后增加,帮助我们建立类型安全的集合 |
|||
|
|||
**本质是数据类型的参数化**: |
|||
|
|||
1. 把类型当作是参数一样进行传递; |
|||
2. <数据类型>只能是引用类型 |
|||
|
|||
好处: |
|||
|
|||
1. 代码可读性更好,不用强制转换 |
|||
2. 程序更加安全,只要编译时间没有警告,运行时期就不会出现ClassCastException异常; |
|||
|
|||
## 类型擦除 |
|||
|
|||
编码时采用泛型写的参数类型,编译器会在编译时去掉,即“类型擦除”,类型参数再编译后会被替换成Object,运行时虚拟机并不知道泛型。 |
|||
|
|||
## 定义泛型 |
|||
|
|||
可以使用任何字符表示标识符,一般用下面的: |
|||
|
|||
| 泛型标记 | 对应单词 | 说明 | |
|||
| -------- | -------- | ------------------------------ | |
|||
| E | Element | 在容器中使用,表示容器中的元素 | |
|||
| T | Type | 表示普通的java类 | |
|||
| K | Key | 表示键,如map中的键key | |
|||
| V | Value | 表示值 | |
|||
| N | Number | 表示数值类型 | |
|||
| ? | | 表示不确定的java类型 | |
|||
|
|||
```java |
|||
//定义泛型类 |
|||
public class Generic<T>{ |
|||
private T flag; |
|||
public void setFlag(T flag){ |
|||
this.flag = flag; |
|||
} |
|||
public T getFlag(){ |
|||
return this.flag; |
|||
} |
|||
} |
|||
``` |
|||
|
|||
```java |
|||
//泛型方法 |
|||
public <泛型表示符号> void getName(泛型表示符号 name){ |
|||
|
|||
} |
|||
public <泛型表示符号> 泛型表示符号 getName(泛型表示符号 name){ |
|||
} |
|||
``` |
|||
|
|||
```java |
|||
//静态方法定义,静态方法中不能使用类定义的泛型 |
|||
public static<泛型表示符号> void getName(泛型表示符号 name){ |
|||
|
|||
} |
|||
public static<泛型表示符号> 泛型表示符号 getName(泛型表示符号 name){ |
|||
} |
|||
``` |
|||
|
|||
```java |
|||
//通配符?,表示类型不确定的 |
|||
public void showFlag(Generic<?> generic){ |
|||
|
|||
} |
|||
|
|||
//通配符上限限定,如下,表示只能是number或者其子类 |
|||
public void showFlag(Generic<? extend Number> generic){ |
|||
|
|||
} |
|||
//通配符下限限定,如下,表示只能是Integer或者其父类 |
|||
public void showFlag(Generic<? super Integer> generic){ |
|||
|
|||
} |
|||
``` |
|||
|
|||
## 泛型总结 |
|||
|
|||
泛型主要用于编译阶段,编译生成的class文件不包含泛型中的类型信息,类型参数再编译后会被替换成Object |
|||
|
|||
1. 基本类型不能用于泛型,但是可以用其对应的包装类 |
|||
|
|||
如 |
|||
`Test<int> t;错误,可以用Test<Integer>t;` |
|||
|
|||
2. 不能通过类型参数创建对象 |
|||
|
|||
T elm = new T();错误 |
|||
|
|||
|
|||
# 容器 |
|||
|
|||
用来容纳和管理数据。 |
|||
|
|||
## 单例集合 |
|||
|
|||
将数据一个一个的进行存储;Collection接口,以单个数据未单位进行存储; |
|||
|
|||
包括: |
|||
|
|||
1. List接口:存储有序,可重复,“动态”数组,实现:ArrayList类、LinkedList类、Vector类 |
|||
2. Set接口,存储无序,不可重复,数学中的“集合”,HashSet、TreeSet |
|||
|
|||
## 双例集合 |
|||
|
|||
基于key与value的结构存储数据,Map接口,数学中的函数y=f(x) |
|||
|
|||
|
|||
# 单例集合 |
|||
|
|||
# Collection |
|||
|
|||
Collection接口时单例集合的根接口,包括两个子接口List、Set接口 |
|||
|
|||
抽象方法: |
|||
|
|||
| 方法 | 说明 | |
|||
| ----------------------------------- | ----------------------------- | |
|||
| boolean add(Object e) | 增加元素 | |
|||
| boolean remove(Object e) | 删除 | |
|||
| Boolean contains(Object e) | 是否包含 | |
|||
| int size() | 元素数量 | |
|||
| Boolean isEmpty() | 是否为空 | |
|||
| void clear() | 清空所有元素 | |
|||
| Iterator iterator() | 获取迭代器,用于遍历所有元素 | |
|||
| Boolean containsAll(Collection c) | 判断是否包含C容器中的所有元素 | |
|||
| Boolean addAll(Collection c) | 将c中所有元素加到该容器 | |
|||
| Boolean removeAll(c) | 移出和c容器中都包含的元素 | |
|||
| Boolean retainAll(c) | 移除c中没有的元素 | |
|||
| Object[] toArray() | 转化成Object数组 | |
|||
|
|||
# list接口 |
|||
|
|||
有序、可重复,有序只是存储有顺序 |
|||
|
|||
| 方法 | 说明 | |
|||
| ------------------------------ | -------------------------------------------- | |
|||
| void add(int index,Object e | 再指定位置插入元素,其余元素后移一位 | |
|||
| Object set(int index, Object e | 修改指定位置的元素,原来位置的元素的值返回 | |
|||
| Object get(int index) | 返回指定位置的元素 | |
|||
| Object remove(int index) | 删除元素,并返回删除的元素 | |
|||
| int indexOf(Object o) | 返回第一匹配元素的索引,若无,则返回-1 | |
|||
| int lastIndexOf(Object o) | 返回最后一个匹配到的元素索引,若无,则返回-1 | |
|||
|
|||
## ArrayList容器类 |
|||
|
|||
LIst接口的实现类,是List存储特征的具体实现, |
|||
|
|||
底层使用数组实现的存储,**特点:查询效率高(使用数组实现),增删效率低(增删后其余元素的索引都要变),线程不安全。** |
|||
|
|||
## 方法使用 |
|||
|
|||
```java |
|||
package container; |
|||
import java.util.ArrayList; |
|||
import java.util.List; |
|||
/** |
|||
* test ArrayList |
|||
*/ |
|||
public class ArrayListTest { |
|||
public static void main(String[] args) { |
|||
//实例化,通过list引用指向ArrayList对象 |
|||
List<String> list = new ArrayList< >(); |
|||
|
|||
//添加元素 |
|||
System.out.println(list.add("tian")); //通过collection接口中的方法添加元素,并返回true |
|||
list.add(1,"zhen"); //通过List接口方法添加元素 |
|||
list.add(2,"dong"); //通过List接口方法添加元素 |
|||
|
|||
//获取元素 |
|||
//System.out.println(list.get(0)); //返回第一个元素 |
|||
for(int i = 0;i< list.size();i++){ |
|||
System.out.println(list.get(i)); |
|||
} |
|||
|
|||
//判断是否包含某元素 |
|||
System.out.println("是否包含tian:"+list.contains("tian")); |
|||
|
|||
//查找元素位置 |
|||
System.out.println(list.indexOf("tian")); //返回第一次出现tian的位置 |
|||
System.out.println(list.lastIndexOf("tian")); //返回最后一次出现tian的位置 |
|||
|
|||
//删除元素 |
|||
String str1 = list.remove(0); //删除第一个元素并返回,List定义,删除指定位置 |
|||
System.out.println("删除的元素:"+ str1); |
|||
|
|||
boolean flag = list.remove("zhen");//删除指定元素,collection方法 |
|||
|
|||
//替换元素 |
|||
String str2 = list.set(0, "Tian"); |
|||
System.out.println("被替换额元素:"+str2); |
|||
|
|||
//判断是否为空 |
|||
System.out.println(list.isEmpty()); |
|||
|
|||
//清空容器 |
|||
|
|||
list.clear(); |
|||
|
|||
//判断是否为空 |
|||
System.out.println(list.isEmpty()); |
|||
|
|||
for(String i : list){ //增强for循环 |
|||
System.out.println(i); |
|||
} |
|||
} |
|||
} |
|||
``` |
|||
|
|||
```java |
|||
//转换为Object[]数组,不能将转换的数组做强制类型转换,只能强制类型转换单个元素,不能是数组 |
|||
Object[] obj1 = list.toArray(); |
|||
for(Object str : obj1){ |
|||
System.out.println(str); |
|||
} |
|||
|
|||
//转换泛型类型数组,指定类型的数组 |
|||
String[] str2 = list.toArray(new String[list.size()]); |
|||
for(String i:str2){ |
|||
System.out.println(i); |
|||
} |
|||
``` |
|||
|
|||
## ArrayList相关 |
|||
|
|||
**数组初始化采用延迟初始化,首先创先长度为0的空数组,使用时再分配长度10的。扩容采用1.5倍** |
|||
|
|||
1. 那我们本身就有数组了,为什么要用ArrayList呢?、 |
|||
|
|||
**原生的数组会有一个特点:你在使用的时候必须要为它创建大小,而ArrayList不用。** |
|||
|
|||
2. ArrayList是怎么实现的吧,为什么ArrayList就不用创建大小呢? |
|||
|
|||
**其实是这样的,我看过源码。当我们new ArrayList()的时候,默认会有一个空的Object数组,大小为0。当我们第一次add添加数据的时候,会给这个数组初始化一个大小,这个大小默认值为10;** |
|||
|
|||
数组的大小是固定的,而ArrayList的大小是可变的;因为ArrayList是实现了**动态扩容**的,假设我们给定数组的大小是10,要往这个数组里边填充元素,我们只能添加10个元素。而ArrayList不一样,ArrayList我们在使用的时候可以往里边添加20个,30个,甚至更多的元素。 |
|||
|
|||
3. ArrayList怎样实现动态扩容的? |
|||
|
|||
|
|||
使用ArrayList在每一次add的时候,它都会先去计算这个数组够不够空间,如果空间是够的,那直接追加上去就好了。如果不够,那就得扩容。在源码里边,有个**grow**方法,每一次扩原来的**1.5**倍。比如说,初始化的值是10嘛。现在我第11个元素要进来了,发现这个数组的空间不够了,所以会扩到15;空间扩完容之后,会调用**arraycopy**来对数组进行拷贝。 |
|||
|
|||
|
|||
## vector容器类 |
|||
|
|||
vector底层也是用数组实现的,相关的方法都加了同步检查,因此是”线程安全,效率低“ |
|||
|
|||
相关方法见Arraylist |
|||
|
|||
**初始化采用立即初始化,扩容采用2倍。** |
|||
|
|||
|
|||
## Stack容器 |
|||
|
|||
**Stack栈容器,是vector的一个子类,实现了标准的后进先出**通过5个方法对vector进行扩展,允许将向量视为堆栈。 |
|||
|
|||
|
|||
**栈中元素的位置从上往下,从1开始,不是从0 |
|||
|
|||
** |
|||
方法: |
|||
|
|||
| 方法 | 用途 | |
|||
| -------------------- | -------------------------------------------- | |
|||
| Boolean empty() | 测试是否为空 | |
|||
| E peek() | 看这个堆栈的顶部的对象,并没有从堆栈中删除它 | |
|||
| E pop() | 删除顶部的对象,并返回该对象的值函数 | |
|||
| E push() | 把一个项目放到堆栈的顶部 | |
|||
| int search(Object o) | 返回元素在栈中的位置,没有则-1 | |
|||
|
|||
```java |
|||
package container; |
|||
|
|||
import java.util.Stack; |
|||
|
|||
/** |
|||
* test stack |
|||
*/ |
|||
public class StackTest { |
|||
public static void main(String[] args) { |
|||
//实例化,不能用list引用,因为stack中定义了新的方法 |
|||
Stack<String > stack = new Stack<>(); |
|||
//将元素添加到栈容器中,压栈 |
|||
String a = stack.push("tian"); |
|||
//System.out.println(a); |
|||
stack.push("zhen"); |
|||
stack.push("dong"); |
|||
|
|||
//获取元素,后进先出,只能从栈顶取pop() |
|||
String pop = stack.pop(); |
|||
System.out.println("删除的元素为:"+pop); |
|||
//测试是否为空empty() |
|||
System.out.println(stack.empty()); |
|||
//返回栈顶元素 |
|||
System.out.println("此时栈顶元素为"+stack.peek()); |
|||
//查看元素的位置search(),注意:栈中元素的位置是从1开始的,不是从0 |
|||
System.out.println("tian的位置:"+stack.search("tian")); |
|||
} |
|||
} |
|||
``` |
|||
|
|||
## LinkedList容器类 |
|||
|
|||
**底层用双向链表实现的存储,特点:查询效率低,增删效率高,线程不安全** |
|||
|
|||
有序,可重复的 |
|||
|
|||
由于 LinkedList 基于链表实现,存储元素过程中,无需像 ArrayList 那样进行扩容。但有得必有失,LinkedList 存储元素的节点需要额外的空间存储前驱和后继的引用。另一方面,LinkedList 在链表头部和尾部插入效率比较高,但在指定位置进行插入时,效率一般。原因是,在指定位置插入需要定位到该位置处的节点,此操作的时间复杂度为 O(N)。 |
|||
|
|||
|
|||
特有方法: |
|||
|
|||
| 方法 | 说明 | |
|||
| ------------------ | -------------------- | |
|||
| void addFirst(E e) | 插入到开头 | |
|||
| void addLast(E e) | 插入到末尾 | |
|||
| getFirst() | 返回第一个元素 | |
|||
| getLast() | 返回最后一个元素 | |
|||
| removeFirst() | 移除第一个元素并返回 | |
|||
| removeLast() | 移除最后一个并返回 | |
|||
| E pop() | 等效于removeFirst() | |
|||
| void push(E e) | 等效于addFirst(E e) | |
|||
| boolean isEmpty() | 判断是否为空 | |
|||
|
|||
```java |
|||
LinkedList<String> dataList = new LinkedList<>(); // 创建 LinkedList |
|||
dataList.add("test"); // 添加数据 |
|||
dataList.add(1, "test1"); // 指定位置,添加数据 |
|||
dataList.addFirst("first"); // 添加数据到头部 |
|||
dataList.addLast("last"); // 添加数据到尾部 |
|||
dataList.get(0); // 获取指定位置数据 |
|||
dataList.getFirst(); // 获取头部数据 |
|||
dataList.getLast(); // 获取尾部数据 |
|||
dataList.remove(1); // 移除指定位置的数据 |
|||
dataList.removeFirst(); // 移除头部数据 |
|||
dataList.removeLast(); // 移除尾部数据 |
|||
dataList.clear(); // 清空数据 |
|||
``` |
|||
|
|||
|
|||
|
|||
# set接口 |
|||
|
|||
set继承自collection,没有新增方法。 |
|||
|
|||
无序,不可重复,无序是指set中的元素没有索引,只能遍历查找;不可重复值不要允许加入重复的元素。 |
|||
|
|||
常用的实现类:HashSet和TreeSet,一般用HashSet. |
|||
|
|||
## Haseset容器类 |
|||
|
|||
Hashset无重复、无序的,是线程不安全的,允许有null元素。采用哈希算法实现,底层实际用HashMap实现,因此**查询和增删效率较高**。 |
|||
|
|||
>**无序**:底层用hashmap存储元素,hashmap底层用的是数组和链表实现元素的存储。元素在数组中存放时(初始化为长度16),并不是有序存放的也不是随机的,而是对元素的哈希值进行运算决定元素在数组中的位置。 |
|||
|
|||
>**不重复**:当两个元素的哈希值进行运算后得到相同的在数组中的位置时,会调用equals()方法判断两个元素是否相同,如果相同,则不会添加,如果不同,则会使用单向链表保存该元素。 |
|||
|
|||
```java |
|||
package container; |
|||
|
|||
import java.util.HashSet; |
|||
import java.util.Set; |
|||
|
|||
public class HashSetTest { |
|||
public static void main(String[] args) { |
|||
//实例化HashSet |
|||
Set<String> s1 = new HashSet<>(); |
|||
//添加元素 |
|||
s1.add("tian"); |
|||
s1.add("zhen"); |
|||
s1.add("dong"); |
|||
|
|||
//获取元素,set中没有索引,没有对应的get方法 |
|||
for(String s : s1){ |
|||
System.out.println(s); //输出结果和添加元素的顺序无关 |
|||
} |
|||
System.out.println("-----------"); |
|||
//删除元素 |
|||
s1.remove("dong"); |
|||
for(String s : s1){ |
|||
System.out.println(s); //输出结果和添加元素的顺序无关 |
|||
} |
|||
//返回元素个数 |
|||
System.out.println("-----------"); |
|||
System.out.println(s1.size()); |
|||
} |
|||
} |
|||
``` |
|||
|
|||
**存储自定义类对象,需要在类中重写equals()和hashCode()** |
|||
|
|||
```java |
|||
package container; |
|||
|
|||
import java.util.Objects; |
|||
|
|||
public class Test { |
|||
private String u1; |
|||
private int a; |
|||
|
|||
public String getU1() { |
|||
return u1; |
|||
} |
|||
|
|||
public void setU1(String u1) { |
|||
this.u1 = u1; |
|||
} |
|||
|
|||
public int getA() { |
|||
return a; |
|||
} |
|||
|
|||
public void setA(int a) { |
|||
this.a = a; |
|||
} |
|||
|
|||
public Test(String u1, int a) { |
|||
this.u1 = u1; |
|||
this.a = a; |
|||
} |
|||
|
|||
public Test() { |
|||
} |
|||
|
|||
@Override |
|||
public boolean equals(Object o) { |
|||
if (this == o) return true; |
|||
if (o == null || getClass() != o.getClass()) return false; |
|||
Test test = (Test) o; |
|||
return a == test.a && Objects.equals(u1, test.u1); |
|||
} |
|||
//重新hashCode |
|||
@Override |
|||
public int hashCode() { |
|||
return Objects.hash(u1, a); |
|||
} |
|||
|
|||
public static void main(String[] args) { |
|||
Test t1 = new Test("tian",12); |
|||
Test t2 = new Test("tian",12); |
|||
System.out.println(t1.hashCode()); |
|||
System.out.println(t2.hashCode()); |
|||
|
|||
} |
|||
} |
|||
``` |
|||
|
|||
## TreeSet容器类 |
|||
|
|||
>可以对元素进行排序的容器,底层用TreeMap实现,内部位置了一个简化版的TreeMap,通过key存储Set元素,内部需要对元素进行排序,因此需要给定排序规则 |
|||
|
|||
排序规则: |
|||
|
|||
1. 通过元素自身实现比较规则,元素自身定义了比较规则; |
|||
2. 通过比较器指定比较规则。 |
|||
|
|||
**1.自定义比较规则** |
|||
|
|||
```java |
|||
public class Users extend comparable<Users>{ |
|||
... |
|||
... |
|||
.. |
|||
//定义比较规则 |
|||
//整数:大,负数:小,0:相等 |
|||
//重写compareTo |
|||
public int compareTo(Users o){ |
|||
if(this.age>o.getUserage()){ |
|||
return 1; |
|||
} |
|||
if(this.age==o.getUserage()){ |
|||
this.username.compareTo(o.username);//username是字符串,String中已经定义了compareTo() |
|||
} |
|||
return -1; |
|||
} |
|||
} |
|||
``` |
|||
|
|||
|
|||
**2.通过比较器实现比较规则** |
|||
创建一个比较器,然后再实例化TreeSet时把比较器传递进去 |
|||
|
|||
```java |
|||
//创建比较器 |
|||
public class UsersComparator implements Comparator<Users>{ |
|||
//定义比较规则 |
|||
//重写 |
|||
public int compare(Users o1,Users o2){ |
|||
if(o1.getUserage>o2.getUserage){ |
|||
return 1; |
|||
} |
|||
return -1; |
|||
} |
|||
} |
|||
.... |
|||
//实例化TreeSet |
|||
Set<Users> s1 = new TreeSet<>( new UsersComparator); |
|||
``` |
|||
|
|||
|
|||
# 双例集合 |
|||
|
|||
## Map接口 |
|||
|
|||
>Map接口中的元素是成对出现的,由键-值两个部分组成,键不可重复,但是值可以重复 |
|||
|
|||
Map常用方法: |
|||
|
|||
| 方法 | 说明 | |
|||
| ----------------------------------- | ---------------------------------------------------------- | |
|||
| V put(K key,V value) | 添加元素对,如果key已有值,则会替换,并会返回被替换的value | |
|||
| void putAll(Map m) | 从指定map中复制映射关系到此map中 | |
|||
| V remove(Object key) | 删除key对应的value并返回value | |
|||
| V get(Object key) | 获取key对应的value | |
|||
| Boolean containsKey(Object key) | 判断是否包含该key | |
|||
| boolean containsValue(Object value) | 判断是否包含该value | |
|||
| Set keySet() | 获取map中所有的key,并存储的set中 | |
|||
| Set<Map.Entry<K,V>> entrySet() | 返回一个Set基于Map.Entry类型包含Map中所有映射 | |
|||
| void clear() | 删除map中所有的映射 | |
|||
|
|||
|
|||
|
|||
## HashMap容器类 |
|||
|
|||
> 采用hash算法实现,是map接口最常用的实现类,底层采用了哈希表存储数据,要求键不能重复,如果发生重复,新的值会替换旧的值,在查找、删除、修改方面都有比较高的效率 |
|||
|
|||
```java |
|||
package container; |
|||
|
|||
import java.util.HashMap; |
|||
import java.util.Map; |
|||
import java.util.Set; |
|||
|
|||
/** |
|||
* 获取hashmap中key对应值的三中方法 |
|||
*/ |
|||
public class HashMapTest { |
|||
public static void main(String[] args) { |
|||
//实例化hashmap |
|||
Map<String ,String> map1 = new HashMap<>(); |
|||
Map<String,String> map2 =new HashMap<>(); |
|||
//添加元素 |
|||
map1.put("a","b"); |
|||
//替换a对应的值并返回被替换的值,若未发生替换,则返回空 |
|||
map1.put("a","A"); |
|||
map1.put("b","B"); |
|||
map1.put("c","C"); |
|||
map2.put("d","D"); |
|||
|
|||
//合并map2到map1,如果有key相同的,map2中的会覆盖map1中的值 |
|||
map1.putAll(map2); |
|||
|
|||
//方法1,通过get方法 |
|||
System.out.println("==========方法一============"); |
|||
System.out.println("a--------"+map1.get("a")); |
|||
System.out.println("b--------"+map1.get("b")); |
|||
System.out.println("c--------"+map1.get("c")); |
|||
|
|||
//方法二,通过keySet |
|||
System.out.println("==========方法二============"); |
|||
Set<String> set1 = map1.keySet(); |
|||
for (String s:set1){ |
|||
System.out.println(s+"-------"+map1.get(s)); |
|||
} |
|||
|
|||
//方法三,通过Map.entry,entry是map中的子接口,有getKey和getValue两个方法 |
|||
System.out.println("==========方法三======="); |
|||
Set<Map.Entry<String,String>> set2 = map1.entrySet(); |
|||
for(Map.Entry<String,String> entry:set2){ |
|||
String key = entry.getKey(); |
|||
String value = entry.getValue(); |
|||
System.out.println(key+"-------"+value); |
|||
} |
|||
} |
|||
} |
|||
|
|||
/* |
|||
==========方法一============ |
|||
a--------A |
|||
b--------B |
|||
c--------C |
|||
==========方法二============ |
|||
a-------A |
|||
b-------B |
|||
c-------C |
|||
==========方法三======= |
|||
a-------A |
|||
b-------B |
|||
c-------C |
|||
``` |
|||
|
|||
|
|||
## hashmap底层存储 |
|||
|
|||
>hashmap底层实现采用了哈希表;数据结构中由数组和链表实现对数据的存储,各自特点如下: |
|||
|
|||
1. 数组:占用空间连续,寻址容易查询速度看,但是增删效率低 |
|||
2. 链表:占用空间不连续,寻址困难,查询速度慢,但是增删效率搞 |
|||
|
|||
>哈希表本质是数组+链表,查询和增删效率高 |
|||
|
|||
|
|||
1. 初始化数组,延迟初始化,调用时通过resize方法生成2<<4=16的数组长度,并进行0.75的扩容;将值传到NODE<K,V>节点类中,再存储到数组中 |
|||
2. 计算hash值:调用key对象的hashcode方法计算key的hashcode值,根据hashcode值计算hash值(值在[0,数组长度-1]之间),公式:hash值=hashcode &(数组长度-1) |
|||
3. 添加元素,根据计算的hash值,放在数组的相应索引下,如果该位置已有索引:如果两个key值相同,则进行覆盖,如果不相同,则在该位置形成单向链表 |
|||
4. 如果链表长度大于8,则转换成红黑树,如果红黑树小于6,则转换为链表 |
|||
|
|||
|
|||
## TreeMap |
|||
|
|||
>TreeMap和HashMap同样实现了map接口。HashMap效率要高于TreeMap,但是TreeMap是可以对键进行排序的,底层基于红黑树实现 |
|||
|
|||
使用TreeMap要给定排序规则: |
|||
|
|||
1. 通过元素自身实现比较规则,元素自身定义了比较规则; |
|||
2. 通过比较器指定比较规则。 |
|||
|
|||
|
|||
# Iterator迭代器接口 |
|||
|
|||
>collection接口继承了Iterator接口,包含一个iterator方法,会返回一个Iterator接口类型的对象,包含了三个方法用于实现对单例容器的迭代处理。 |
|||
|
|||
方法: |
|||
|
|||
| 方法 | 说明 | |
|||
| ----------------- | ---------------------------------------------------------- | |
|||
| boolean hasNext() | 判断游标当前位置是否铀元素,有返回True | |
|||
| Object next() | 获取当前游标所在位置的元素,并将游标移动到下一位置 | |
|||
| void remove() | 删除游标当前位置元素,在执行完next后使用,并且只能执行一次 | |
|||
|
|||
```java |
|||
package container; |
|||
|
|||
import java.util.ArrayList; |
|||
import java.util.Iterator; |
|||
import java.util.List; |
|||
|
|||
public class IterotorTest { |
|||
public static void main(String[] args) { |
|||
//实例化容器 |
|||
List<String> list = new ArrayList<>(); |
|||
list.add("a"); |
|||
list.add("b"); |
|||
list.add("c"); |
|||
//迭代器 |
|||
Iterator<String> iterator =list.iterator(); |
|||
//通过while循环获取元素 |
|||
System.out.println("通过while========="); |
|||
while (iterator.hasNext()){ |
|||
String value = iterator.next(); |
|||
System.out.println(value); |
|||
} |
|||
//通过for |
|||
System.out.println("通过for=====");; |
|||
for(Iterator<String> i = list.iterator();i.hasNext();){ |
|||
String value = i.next(); |
|||
System.out.println(value); |
|||
} |
|||
} |
|||
} |
|||
``` |
|||
|
|||
# Collections工具类 |
|||
|
|||
>Collections是一个工具类,提供了对Set、List、Map进行排序、填充、查找元素的辅助方法,该类中所有的方法都为静态方法。 |
|||
|
|||
常用方法: |
|||
|
|||
| 方法 | 说明 | |
|||
| ----------------------------- | ---------------------------------------------------------- | |
|||
| void sort(List) | 对list容器内的元素排序,规则按照升序 | |
|||
| void shuffle(List) | 对List随机排列,打乱 | |
|||
| void reverse(List) | 逆序排列 | |
|||
| void fill(List,Object) | 用一个特定的对象重写整个List容器 | |
|||
| int binarySearch(List,Object) | 对于顺序的容器,采用折半查找法查找特定对象,放回对象的索引 | |
|||
|
|||
```java |
|||
package container; |
|||
|
|||
import java.util.ArrayList; |
|||
import java.util.Collections; |
|||
import java.util.Iterator; |
|||
import java.util.List; |
|||
|
|||
public class CollectionsMethodsTest { |
|||
public static void main(String[] args) { |
|||
//实例化容器 |
|||
List<String> list = new ArrayList<>(); |
|||
list.add("c"); |
|||
list.add("a"); |
|||
list.add("b"); |
|||
//sort排序 |
|||
Collections.sort(list); |
|||
for (Iterator<String > i=list.iterator();i.hasNext();){ |
|||
String s = i.next(); |
|||
System.out.println(s); |
|||
} |
|||
System.out.println("================"); |
|||
//shuffle打乱顺序 |
|||
Collections.shuffle(list); |
|||
for (Iterator<String > i=list.iterator();i.hasNext();){ |
|||
String s = i.next(); |
|||
System.out.println(s); |
|||
} |
|||
} |
|||
} |
|||
``` |
|||
|
|||
@ -0,0 +1,647 @@ |
|||
--- |
|||
title: java常用类 |
|||
author: TianZD |
|||
top: true |
|||
cover: true |
|||
toc: true |
|||
mathjax: false |
|||
summary: JavaSE基础,java中的常用类学习笔记,粗略学了一下,没有参考价值 |
|||
tags: |
|||
- java基础 |
|||
- java常用类 |
|||
- 学习笔记 |
|||
categories: |
|||
- java |
|||
reprintPolicy: cc_by |
|||
abbrlink: 6c6d8dca |
|||
date: 2022-04-29 10:57:09 |
|||
coverImg: |
|||
img: |
|||
password: |
|||
--- |
|||
|
|||
|
|||
[toc] |
|||
|
|||
# 包装类 |
|||
|
|||
java是面向对象的语言,但不是纯面向对象的,因为基本数据类型不是对象,但是在实际应用的时候经常需要把基本数据类型转化成对象,为了解决这个问题,java在设计类时,为每一个基本数据类型设计了一个对应的类进行代表,统称为包装类(wrapper class) |
|||
|
|||
包装类均位于java.lang包中: |
|||
|
|||
| 基本数据类型 | 包装类 | |
|||
| :------------: | :-------: | |
|||
| byte | Byte | |
|||
| boolean | Boolean | |
|||
| short | Short | |
|||
| char | Character | |
|||
| int | Integer | |
|||
| long | Long | |
|||
| float | Float | |
|||
| double|Double | | |
|||
|
|||
其中8种整型的为数字,具有统一父类:抽象类Number |
|||
|
|||
```java |
|||
package JavaStudy; |
|||
|
|||
/** |
|||
* test Interger 包装类 |
|||
*/ |
|||
public class IntegerTest { |
|||
public static void main(String[] args) { |
|||
//基本数据类型转换为对象 |
|||
Integer i = new Integer(10); //已被废弃,不推荐 |
|||
Integer i1 = Integer.valueOf(10); //推荐 |
|||
//对象转换为基本数据类型 |
|||
int i2 = i1.intValue(); |
|||
double d = i1.doubleValue(); |
|||
//System.out.println(i2); |
|||
System.out.println(i2+"\t"+d); |
|||
//System.out.println(String.valueOf(i2)+"\t"+Double.toString(d)+"\t"+d); |
|||
//将字符串转为包装类对象 |
|||
Integer i3 = Integer.valueOf("12"); |
|||
Integer i4 = Integer.parseInt("23"); |
|||
System.out.println(i3+"\t"+i4); |
|||
//包装类对象转为字符串,字符串不是基本数据类型,属于引用数据类型 |
|||
String str = i3.toString(); |
|||
System.out.println(str); |
|||
|
|||
//*自动装箱* |
|||
Integer a = 300; //编译器帮你改成:Integer a = Integer.valueof(300); |
|||
|
|||
//自动拆箱 |
|||
int b = a; //编译器帮你改成int b = a.intValue(); |
|||
} |
|||
} |
|||
``` |
|||
|
|||
# String类 |
|||
|
|||
用的最多的类; |
|||
|
|||
## String基础 |
|||
|
|||
1. String类又称作不可变字符序列 |
|||
2. 位于java.lang包 |
|||
3. java字符串就是Unicode字符序列,java就是j、a、v、a组成 |
|||
|
|||
|
|||
|
|||
# String 方法 |
|||
|
|||
## 创建字符串 |
|||
|
|||
创建一个String对象,并初始化一个值。 |
|||
String类是不可改变的,一旦创建了一个String对象,它的值就不能改变了。 |
|||
如果想对字符串做修改,需要使用StringBuffer&StringBuilder类。 |
|||
|
|||
```java |
|||
//直接创建方式 |
|||
String str1 = "abc"; |
|||
//提供一个 字符数组 参数来初始化字符串 |
|||
char[] strarray = {'a','b','c'}; |
|||
String str2 = new String(strarray); |
|||
|
|||
``` |
|||
|
|||
## 字符串遍历 |
|||
|
|||
```java |
|||
public static void main(String[] args) { |
|||
String str = "keep walking!!!"; |
|||
//方法一 |
|||
char[] charArray = str.toCharArray(); |
|||
for (char i:charArray){ |
|||
System.out.println(i); |
|||
} |
|||
/*for (int i = 0; i < charArray.length; i++) { |
|||
System.out.println(c[i]); |
|||
}*/ |
|||
|
|||
// 方法二 |
|||
for (int i = 0; i < str.length(); i++) { |
|||
System.out.println(str.charAt(i)); |
|||
} |
|||
|
|||
//方法三 |
|||
for (int i = 0; i < str.length(); i++) { |
|||
System.out.println(str.substring(i, i + 1)); |
|||
} |
|||
} |
|||
``` |
|||
|
|||
## 字符串长度获取 |
|||
|
|||
int length()方法:返回字符串对象包含的字符数。 |
|||
|
|||
```java |
|||
int len = str.length(); |
|||
``` |
|||
|
|||
## 连接字符串 |
|||
|
|||
String concat(String str):连接两个字符串的方法 |
|||
或者直接用‘+’操作符来连接 |
|||
|
|||
```java |
|||
//String对象的连接 |
|||
str1.concat(str2); |
|||
|
|||
"两个字符串连接结果:"+str1+str2; |
|||
``` |
|||
|
|||
## 字符串查找 |
|||
|
|||
int indexOf(String s):字符串s在指定字符串中首次出现的索引位置,如果没有检索到字符串s,该方法返回-1 |
|||
|
|||
int lastIndexOf(String s):字符串s在指定字符串中最后一次出现的索引位置,如果没有检索到字符串s,该方法返回-1; |
|||
|
|||
如果s是空字符串,则返回的结果与length方法的返回结果相同,即返回整个字符串的长度。 |
|||
如果s是空字符串,则返回的结果与length方法的返回结果相同,即返回整个字符串的长度。java |
|||
|
|||
```java |
|||
int idx = str.indexOf("a");//字符a在str中首次出现的位置 |
|||
int idx = str.lastIndexOf("a"); |
|||
|
|||
``` |
|||
|
|||
## 获取指定位置的字符串 |
|||
|
|||
char charAt(int index)方法:返回指定索引出的字符 |
|||
|
|||
```java |
|||
String str = "abcde"; |
|||
char thischar = str.charAt(3);//索引为3的thischar是"d" |
|||
|
|||
``` |
|||
|
|||
## 获取子字符串 |
|||
|
|||
String substring()方法:实现截取字符串,利用字符串的下标索引来截取(字符串的下标是从0开始的,在字符串中空格占用一个索引位置) |
|||
|
|||
substring(int beginIndex):截取从指定索引位置开始到字符串结尾的子串 |
|||
substring(int beginIndex, int endIndex):从beginIndex开始,到endIndex结束(不包括endIndex) |
|||
|
|||
```java |
|||
String str = "abcde"; |
|||
String substr1 = str.substring(2);//substr1为"cde" |
|||
String substr2 = str.substring(2,4);//substr2为"cd" |
|||
|
|||
``` |
|||
|
|||
## 去除字符串首尾的空格() |
|||
|
|||
String trim()方法 |
|||
|
|||
```java |
|||
String str = " ab cde "; |
|||
String str1 = str.trim();//str1为"ab cde" |
|||
``` |
|||
|
|||
## 字符串替换 |
|||
|
|||
1. String replace(char oldChar, char newChar):将指定的字符/字符串oldchar全部替换成新的字符/字符串newChar |
|||
2. String replaceAll(String regex, String replacement):使用给定的参数 replacement替换字符串所有匹配给定的正则表达式的子字符串 |
|||
3. String replaceFirst(String regex, String replacement):使用给定replacement 替换此字符串匹配给定的正则表达式的第一个子字符串 |
|||
regex是正则表达式,替换成功返回替换的字符串,替换失败返回原字符串 |
|||
|
|||
```java |
|||
String str = "abcde"; |
|||
String newstr = str.replace("a","A");//newstr为"Abcde" |
|||
``` |
|||
|
|||
## 判断字符串的开始与结尾 |
|||
|
|||
boolean startsWith() |
|||
|
|||
1. boolean startsWith(String prefix):判断此字符串是否以指定的后缀prefix开始 |
|||
2. boolean startsWith(String prefix, int beginidx):判断此字符串中从beginidx开始的子串是否以指定的后缀prefix开始 |
|||
boolean endsWith(String suffix):判断此字符串是否以指定的后缀suffix结束 |
|||
|
|||
```java |
|||
String str = "abcde"; |
|||
boolean res = str.startsWith("ab");//res为true |
|||
boolean res = str.StartsWith("bc",1);//res为true |
|||
boolean res = str.endsWith("de");//res为true |
|||
``` |
|||
|
|||
## 判断字符串是否相等 |
|||
|
|||
boolean equals(Object anObject):将此字符串与指定的对象比较,区分大小写 |
|||
boolean equalsIgnoreCase(String anotherString):将此 String 与另一个 String 比较,不考虑大小写 |
|||
|
|||
```java |
|||
String str1 = "abcde"; |
|||
String str2 = str1;//字符串str1和str2都是一个字符串对象 |
|||
String str3 = "ABCDE"; |
|||
boolean isEqualed = str1.equals(str2);//返回true |
|||
boolean isEqualed = str1.equals(str3);//返回false |
|||
boolean isEqualed = str1.equlasIgnoreCase(str3);//返回true |
|||
|
|||
``` |
|||
|
|||
## 比较两个字符串 |
|||
|
|||
int compareTo(Object o):把这个字符串和另一个对象比较。 |
|||
int compareTo(String anotherString):按字典顺序比较两个字符串。 |
|||
比较对应字符的大小(ASCII码顺序),如果参数字符串等于此字符串,则返回值 0;如果此字符串小于字符串参数,则返回一个小于 0 的值;如果此字符串大于字符串参数,则返回一个大于 0 的值。 |
|||
|
|||
```java |
|||
String str1 = "abcde"; |
|||
String str2 = "abcde123"; |
|||
String str3 = str1; |
|||
int res = str1.compareTo(str2);//res = -3 |
|||
int res = str1.compareTo(str3);//res = 0 |
|||
int res = str2.compareTo(str1);//res = 3 |
|||
|
|||
``` |
|||
|
|||
## 把字符串转换为相应的数值 |
|||
|
|||
String转int型: |
|||
|
|||
```java |
|||
//第一种 |
|||
int i = Integer.parseInt(String str) |
|||
//第二种 |
|||
int i = Integer.valueOf(s).intValue(); |
|||
|
|||
``` |
|||
|
|||
String转long型: |
|||
|
|||
```java |
|||
long l = Long.parseLong(String str); |
|||
1 |
|||
``` |
|||
|
|||
String转double型: |
|||
|
|||
```java |
|||
double d = Double.valueOf(String str).doubleValue();//doubleValue()不要也可 |
|||
double d = Double.parseDouble(str); |
|||
|
|||
``` |
|||
|
|||
int转string型: |
|||
|
|||
```java |
|||
//第一种 |
|||
String s = String.valueOf(i); |
|||
//第二种 |
|||
String s = Integer.toString(i); |
|||
//第三种 |
|||
String s = "" + i; |
|||
|
|||
``` |
|||
|
|||
## 字符大小写转换 |
|||
|
|||
String toLowerCase():将字符串中的所有字符从大写字母改写为小写字母 |
|||
String toUpperCase():将字符串中的所有字符从小写字母改写为大写字母 |
|||
|
|||
```java |
|||
String str1 = "abcde"; |
|||
String str2 = str1.toUpperCase();//str2 = "ABCDE"; |
|||
String str3 = str2.toLowerCase();//str3 = "abcde"; |
|||
|
|||
``` |
|||
|
|||
## 字符串分割 |
|||
|
|||
String[] split():根据匹配给定的正则表达式来拆分字符串,将分割后的结果存入字符数组中。 |
|||
|
|||
String[] split(String regex):regex为正则表达式分隔符, . 、 $、 | 和 * 等转义字符,必须得加 \\;多个分隔符,可以用 | 作为连字符。 |
|||
String[] split(String regex, int limit):limit为分割份数 |
|||
|
|||
```java |
|||
String str = "Hello World A.B.C" |
|||
String[] res = str.split(" ");//res = {"Hello","World","A.B.C"} |
|||
String[] res = str.split(" ",2);//res = {"Hello","World A.B.C"} |
|||
String[] res = str.split("\\.");//res = {"Hello World A","B","C"} |
|||
|
|||
String str = "A=1 and B=2 or C=3" |
|||
String[] res = str.split("and|or");//res = {"A=1 "," B=2 "," C=3"} |
|||
|
|||
``` |
|||
|
|||
## 字符数组与字符串的转换 |
|||
|
|||
public String(char[] value) :通过char[]数组来创建字符串 |
|||
char[] toCharArray():将此字符串转换为一个新的字符数组。 |
|||
|
|||
```java |
|||
String str = "abcde"; |
|||
char mychar[] = str.toCharArray();//char[0] = 'a'; char[1] = 'b'... |
|||
|
|||
``` |
|||
|
|||
## 字符串与byte数组的转换 |
|||
|
|||
byte[] getBytes() |
|||
|
|||
byte[] getBytes():使用平台的默认字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中。 |
|||
byte[] getBytes(String charsetName):使用指定的字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中。 |
|||
|
|||
```java |
|||
byte[] Str2 = Str1.getBytes(); |
|||
|
|||
|
|||
``` |
|||
|
|||
## StringBuffer&StringBuilder类 |
|||
|
|||
与String类最大的不同在于这两个类可以对字符串进行修改。 |
|||
StringBuilder相较StringBuffer来说速度较快,多数情况下使用StringBuilder,但是StringBuilder的方法不是线性安全的(不能同步访问),所以在应用程序要求线程安全的情况下,必须使用StringBuffer。 |
|||
|
|||
## 创建StringBuffer字符串 |
|||
|
|||
```java |
|||
StringBuffer str = new StringBuffer(""); |
|||
``` |
|||
|
|||
## 添加字符(最常用方法) |
|||
|
|||
public StringBuffer append(String s):将指定的字符串追加到字符序列中 |
|||
|
|||
```java |
|||
str.append("abc");//此时str为“abc” |
|||
``` |
|||
|
|||
## 删除字符串中的指定字符 |
|||
|
|||
public delete(int start,int end):移除此序列中的子字符串的内容 |
|||
|
|||
public deleteCharAt(int i):删除指定位置的字符 |
|||
|
|||
```java |
|||
str.delete(0,1);//此时str为“c” |
|||
str.deleteCharAt(str.length()-1);//删除最后一个字符 |
|||
|
|||
``` |
|||
|
|||
## 翻转字符串 |
|||
|
|||
public StringBuffer reverse() |
|||
|
|||
``` |
|||
str.reverse(); |
|||
|
|||
``` |
|||
|
|||
## 换字符串中内容 |
|||
|
|||
replace(int start,int end,String str):用String类型的字符串str替换此字符串的子字符串中的内容 |
|||
|
|||
```java |
|||
String s = "1"; |
|||
str.replace(1,1,s);//此时str为"a1c" |
|||
|
|||
``` |
|||
|
|||
## 插入字符 |
|||
|
|||
public insert(int offset, int i):将int参数形式的字符串表示形式插入此序列中 |
|||
|
|||
```java |
|||
str.insert(1,2); |
|||
``` |
|||
|
|||
## 字符串长度 |
|||
|
|||
int length():返回长度(字符数) |
|||
void setLength(int new Length):设置字符序列的长度 |
|||
|
|||
```java |
|||
str.length(); |
|||
str.setLength(4); |
|||
``` |
|||
|
|||
## 当前容量 |
|||
|
|||
int capacity():获取当前容量 |
|||
void ensureCapacity(int minimumCapacity):确保容量小于指定的最小值 |
|||
|
|||
```java |
|||
str.capacity(); |
|||
``` |
|||
|
|||
## 将其转变为String |
|||
|
|||
String toString() |
|||
|
|||
```java |
|||
str.toString();//将StringBuffer类型的序列转变为String类型的字符串 |
|||
``` |
|||
|
|||
## 设置指定索引处的字符 |
|||
|
|||
void setCharAt(int index,char ch):将给定索引处的字符设置为ch |
|||
|
|||
其余方法和String类型的方法大致相同。 |
|||
|
|||
|
|||
|
|||
# MathMethod |
|||
|
|||
 |
|||
|
|||
|
|||
|
|||
# Random |
|||
|
|||
```java |
|||
Random rand = new Random(); |
|||
|
|||
//[0,1) 之间的double类型数据 |
|||
a = rand.nextDouble(); |
|||
//随机int类型允许范围之内的整形数据 |
|||
b = rand.nextInt(); |
|||
//随机生成[0,1)之间的float类型的数据 |
|||
c = rand.nextFloat(); |
|||
//随机boolean |
|||
d = rand.nextBoolean(); |
|||
//随机[0,10)的int |
|||
e = rand.nextInt(10) |
|||
``` |
|||
|
|||
# TimeClass |
|||
|
|||
|
|||
# 用long变量的值表示时间。 |
|||
|
|||
```java |
|||
long now = System.currentTimeMillis() //获取现在时间,用距离基准时间的毫秒数表示 |
|||
|
|||
Date d1 = new Date() //获取当前时间,年月日表示 |
|||
d1.getTime() //获取当前时间对应的毫秒数 |
|||
|
|||
|
|||
``` |
|||
|
|||
# DateFormat类 |
|||
|
|||
把时间对象转化成指定格式的字符串,是一个抽象类,一般使用其子类SimpleDateFormat类 |
|||
|
|||
```java |
|||
import java.text.DateFormat; |
|||
import java.text.ParseException; |
|||
import java.text.SimpleDateFormat; |
|||
import java.util.Date; |
|||
|
|||
/** |
|||
* 测试时间对象和字符串相互转换 |
|||
* 使用DateFormat、SimpleDATe Format |
|||
*/ |
|||
|
|||
public class TestDateFormat { |
|||
public static void main(String[] args) throws ParseException { |
|||
//定义日期的格式,可以自己定义 |
|||
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss"); |
|||
//SimpleDateFormat df = new SimpleDateFormat("今年第几周,第几天"); |
|||
|
|||
//将字符串转为时间对象 |
|||
Date d1 = df.parse("2021-06-03 19:40:00"); |
|||
System.out.println(d1.getTime()); //d1.getTime()获取时间对应的毫秒数 |
|||
|
|||
//将Date对象转化成字符串 |
|||
Date d2 = new Date(1000L*3600*23); |
|||
String str1 = df.format(d2); |
|||
System.out.println(str1); |
|||
|
|||
} |
|||
} |
|||
``` |
|||
|
|||
|
|||
# Calendar类 |
|||
|
|||
Calendar是一个抽象类,GregorianCalendar类是其子类,使用的是公历; |
|||
|
|||
月份的表示,0表示一月。 周日用1表示,周六用7表示。 |
|||
|
|||
```java |
|||
package JavaStudy; |
|||
|
|||
import java.awt.desktop.SystemEventListener; |
|||
import java.util.Calendar; |
|||
import java.util.Date; |
|||
import java.util.GregorianCalendar; |
|||
|
|||
/** |
|||
* 测试Calendar类和GregorianCalendar类 |
|||
*/ |
|||
|
|||
public class TestCalendar { |
|||
public static void main(String[] args) { |
|||
//生成一个日期,2021年6月3日 |
|||
GregorianCalendar calendar = new GregorianCalendar(2021,5,3,19,59,00) ; |
|||
|
|||
int year = calendar.get(Calendar.YEAR); //print:2021 |
|||
int month = calendar.get(Calendar.MONTH); //print : 5 |
|||
int day = calendar.get(Calendar.DAY_OF_MONTH); //print:3 |
|||
int day2 = calendar.get(Calendar.DATE); //calendar.date = calendar.day_of_mouth |
|||
int date = calendar.get(Calendar.DAY_OF_WEEK); //print 4 |
|||
System.out.println(year); |
|||
System.out.println(month); |
|||
System.out.println(day); |
|||
System.out.println(day2); |
|||
System.out.println(date); |
|||
|
|||
//set date |
|||
GregorianCalendar calendar2 = new GregorianCalendar( ); |
|||
|
|||
calendar2.set(Calendar.YEAR,2021); //set year = 2021 |
|||
calendar2.set(Calendar.MONTH,5); //set monty = 5 |
|||
calendar2.add(Calendar.MONTH, -4 ); //set month = month -4 |
|||
|
|||
|
|||
//日历和时间转换 |
|||
Date d= calendar.getTime(); // calendar to date |
|||
GregorianCalendar calendar4 = new GregorianCalendar(); |
|||
calendar4.setTime(new Date()); //date to calendar |
|||
} |
|||
} |
|||
``` |
|||
|
|||
|
|||
|
|||
# File |
|||
|
|||
|
|||
|
|||
File用来表示文件和文件夹 |
|||
|
|||
```java |
|||
package JavaStudy; |
|||
|
|||
import java.awt.desktop.SystemEventListener; |
|||
import java.io.File; |
|||
import java.io.IOException; |
|||
import java.util.Date; |
|||
|
|||
/** |
|||
* File类 |
|||
*/ |
|||
|
|||
public class TestFile { |
|||
public static void main(String[] args) throws IOException { |
|||
System.out.println(System.getProperty("user.dir")); //获取当前项目路径 |
|||
File f1 = new File("e:/movies/1.mp4"); //文件 |
|||
File f2 = new File("e:/movies.mp4"); //文件夹 |
|||
File f3 = new File("a.txt"); //相对路径,默认放在user.dir目录下 |
|||
f2.createNewFile(); //创建文件夹f2 |
|||
f3.createNewFile(); //创建文件 |
|||
//f1.createNewFile(); |
|||
System.out.println(f2.exists()); //文件是否存在 |
|||
System.out.println(f2.isDirectory()); //是否是目录 |
|||
System.out.println(f2.isFile()); //是否是文件夹 |
|||
System.out.println(new Date(f2.lastModified())); //最后修改时间 |
|||
System.out.println(f2.length()); //文件大小 |
|||
System.out.println(f2.getName()); //文件名字 |
|||
System.out.println(f2.getPath()); //文件路径 |
|||
|
|||
|
|||
f2.delete(); //删除对应的文件 |
|||
f3.delete(); |
|||
|
|||
File f1 = new File("e:/movies/1"); //目录 |
|||
|
|||
boolean flag = f1.mkdir(); //创建一个目录,中间目录缺失的话,则创建失败 |
|||
System.out.println(flag); //目录创建失败 |
|||
|
|||
boolean flag1 = f1.mkdirs(); //创建多个目录,中间目录缺失的话,则创建缺失的目录 |
|||
System.out.println(flag1); //目录创建 |
|||
|
|||
|
|||
} |
|||
} |
|||
|
|||
``` |
|||
|
|||
|
|||
# enum枚举 |
|||
|
|||
本质上也是类 |
|||
|
|||
```java |
|||
enum 枚举名{ |
|||
枚举体(常量列表) |
|||
} |
|||
|
|||
//创建枚举类型 |
|||
enum Season{ |
|||
SPRING,SUMMER,AUTUMN,WINDER |
|||
} |
|||
|
|||
//枚举遍历 |
|||
for(Season k:Season.values()){ |
|||
..... |
|||
} |
|||
|
|||
|
|||
``` |
|||
|
|||
|
|||
|
|||
@ -0,0 +1,938 @@ |
|||
--- |
|||
title: 剑指offer-java-未完成 |
|||
author: TianZD |
|||
top: true |
|||
cover: true |
|||
toc: true |
|||
mathjax: false |
|||
summary: 剑指offer-java-未完成,粗略学了一下,没有参考价值 |
|||
tags: |
|||
- 刷题 |
|||
- Java |
|||
- 学习笔记 |
|||
categories: |
|||
- java |
|||
reprintPolicy: cc_by |
|||
abbrlink: 24101bf4 |
|||
date: 2022-04-29 10:44:28 |
|||
coverImg: |
|||
img: |
|||
password: |
|||
--- |
|||
|
|||
|
|||
|
|||
[toc] |
|||
|
|||
# 二维数组中的查找-中等 |
|||
|
|||
在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。 |
|||
|
|||
[ |
|||
[1,2,8,9], |
|||
[2,4,9,12], |
|||
[4,7,10,13], |
|||
[6,8,11,15] |
|||
] |
|||
|
|||
给定 target = 7,返回 true。 |
|||
|
|||
给定 target = 3,返回 false。 |
|||
|
|||
```java |
|||
//方法1,时间复杂度O(n2),运行时间 9ms,占用内存 9800KB |
|||
public class Solution { |
|||
public boolean Find(int target, int [][] array) { |
|||
for(int i = 0; i< array.length;i++){ |
|||
for(int j = 0; j<array[i].length;j++){ |
|||
if (array[i][j]==target) |
|||
return true; |
|||
} |
|||
} |
|||
return false; |
|||
} |
|||
} |
|||
|
|||
//方法2,采用二分法,从左下角开始,一次排除一行,时间复杂度O(n) |
|||
public class Solution { |
|||
public boolean Find(int target, int [][] array) { |
|||
int rows = array.length; |
|||
if(rows == 0){ |
|||
return false; |
|||
} |
|||
int cols = array[0].length; |
|||
int row = rows -1; |
|||
int col = 0; |
|||
while(row>=0&&col<cols){ |
|||
if(array[row][col]==target){ |
|||
return true; |
|||
}else if(array[row][col]<target){ |
|||
col++; |
|||
}else{ |
|||
row--; |
|||
} |
|||
} |
|||
return false; |
|||
} |
|||
} |
|||
``` |
|||
|
|||
# 替换空格-简单 |
|||
|
|||
请实现一个函数,把字符串 s 中的每个空格替换成"%20"。 |
|||
|
|||
示例: |
|||
|
|||
``` |
|||
输入:s = "We are happy." |
|||
输出:"We%20are%20happy." |
|||
``` |
|||
|
|||
```java |
|||
//方法1,机灵鬼 |
|||
class Solution { |
|||
public String replaceSpace(String s) { |
|||
if(s == null){ |
|||
return s; |
|||
} |
|||
return s.replaceAll(" ","%20"); |
|||
} |
|||
} |
|||
|
|||
//方法2, |
|||
public class Solution { |
|||
/** |
|||
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可 |
|||
* |
|||
* |
|||
* @param s string字符串 |
|||
* @return string字符串 |
|||
*/ |
|||
public String replaceSpace (String s) { |
|||
// write code here |
|||
StringBuilder sb = new StringBuilder(); |
|||
for(int i=0;i<s.length();i++){ |
|||
char temp = s.charAt(i); |
|||
if(temp ==' '){ |
|||
sb.append("%20"); |
|||
}else{ |
|||
sb.append(temp); |
|||
} |
|||
} |
|||
return sb.toString(); |
|||
} |
|||
} |
|||
``` |
|||
|
|||
# 从尾到头打印链表-简单 |
|||
|
|||
输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。 |
|||
|
|||
示例 |
|||
|
|||
``` |
|||
输入:head = [1,3,2] |
|||
输出:[2,3,1] |
|||
``` |
|||
|
|||
```java |
|||
//方法1,递归 |
|||
/** |
|||
* Definition for singly-linked list. |
|||
* public class ListNode { |
|||
* int val; |
|||
* ListNode next; |
|||
* ListNode(int x) { val = x; } |
|||
* } |
|||
*/ |
|||
class Solution { |
|||
int i =0; |
|||
int[]list; |
|||
int j=0; |
|||
public int[] reversePrint(ListNode head) { |
|||
|
|||
ListNode node = head; |
|||
//获取数组长度,或者直接用ArrayList实现 |
|||
while(node != null){ |
|||
node = node.next; |
|||
i++; |
|||
} |
|||
|
|||
reverse(head); |
|||
return list; |
|||
|
|||
} |
|||
|
|||
void reverse(ListNode head){ |
|||
ListNode node1 = head; |
|||
if(node1 == null){ |
|||
list=new int[i] ; |
|||
|
|||
}else{ |
|||
reverse(node1.next); |
|||
list[j++] = node1.val; |
|||
} |
|||
|
|||
|
|||
} |
|||
} |
|||
|
|||
//方法2,方法1的进阶版,统计长度后初始化数组 |
|||
/** |
|||
* Definition for singly-linked list. |
|||
* public class ListNode { |
|||
* int val; |
|||
* ListNode next; |
|||
* ListNode(int x) { val = x; } |
|||
* } |
|||
*/ |
|||
class Solution { |
|||
int i =0; |
|||
int[]list; |
|||
int j=0; |
|||
public int[] reversePrint(ListNode head) { |
|||
ListNode node = head; |
|||
reverse(node); |
|||
return list; |
|||
} |
|||
|
|||
void reverse(ListNode head){ |
|||
if(head == null){ |
|||
list=new int[i] ; |
|||
}else{ |
|||
i++; |
|||
reverse(head.next); |
|||
list[j++] = head.val; |
|||
} |
|||
} |
|||
} |
|||
|
|||
//方法3,栈 |
|||
/** |
|||
* Definition for singly-linked list. |
|||
* public class ListNode { |
|||
* int val; |
|||
* ListNode next; |
|||
* ListNode(int x) { val = x; } |
|||
* } |
|||
*/ |
|||
class Solution { |
|||
public int[] reversePrint(ListNode head) { |
|||
Stack<Integer> sk = new Stack<>(); |
|||
ListNode node = head; |
|||
while(node!=null){ |
|||
sk.push(node.val); |
|||
node = node.next; |
|||
} |
|||
int size = sk.size(); |
|||
int[] list = new int[size]; |
|||
for(int i = 0; i<size;i++){ |
|||
list[i] = sk.pop(); |
|||
} |
|||
return list; |
|||
} |
|||
} |
|||
|
|||
//方法4 |
|||
/** |
|||
* Definition for singly-linked list. |
|||
* public class ListNode { |
|||
* int val; |
|||
* ListNode next; |
|||
* ListNode(int x) { val = x; } |
|||
* } |
|||
*/ |
|||
class Solution { |
|||
public int[] reversePrint(ListNode head) { |
|||
int len = 0; |
|||
ListNode node = head; |
|||
while(node!=null){ |
|||
len++; |
|||
node = node.next; |
|||
} |
|||
int[] list = new int[len]; |
|||
node = head; |
|||
for(int i=0; i<len; i++){ |
|||
list[len-i-1] = node.val; |
|||
node = node.next; |
|||
} |
|||
return list; |
|||
} |
|||
} |
|||
``` |
|||
|
|||
# 数组中重复的数字-简单 |
|||
|
|||
找出数组中重复的数字。 |
|||
|
|||
|
|||
在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。 |
|||
|
|||
``` |
|||
输入:[2, 3, 1, 0, 2, 5, 3] |
|||
输出:2 或 3 |
|||
``` |
|||
|
|||
```java |
|||
//直接用两个for循环会导致超时 |
|||
//方法1,使用hashset,使用list的话会超时,即时在末尾增加也会超时 |
|||
class Solution { |
|||
public int findRepeatNumber(int[] nums) { |
|||
HashSet<Integer> al = new HashSet<>(); |
|||
for(int n:nums){ |
|||
if(al.contains(n)){ |
|||
return n; |
|||
} |
|||
al.add(n); |
|||
} |
|||
return -1; |
|||
} |
|||
} |
|||
//方法2,原地交换 |
|||
class Solution { |
|||
public int findRepeatNumber(int[] nums) { |
|||
int n = 0; |
|||
while(n<nums.length){ |
|||
if(nums[n]==n){ |
|||
n++; |
|||
continue; |
|||
} |
|||
if(nums[nums[n]]==nums[n])return nums[n]; |
|||
int temp = nums[nums[n]]; |
|||
nums[nums[n]]=nums[n]; |
|||
nums[n] = temp; |
|||
} |
|||
return -1; |
|||
} |
|||
} |
|||
``` |
|||
|
|||
|
|||
# 重建二叉树-难度中等 |
|||
|
|||
输入某二叉树的前序遍历和中序遍历的结果,请重建该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。 |
|||
|
|||
``` |
|||
前序遍历 preorder = [3,9,20,15,7] |
|||
中序遍历 inorder = [9,3,15,20,7] |
|||
|
|||
3 |
|||
/ \ |
|||
9 20 |
|||
/ \ |
|||
15 7 |
|||
``` |
|||
|
|||
|
|||
```java |
|||
/** |
|||
* Definition for a binary tree node. |
|||
* public class TreeNode { |
|||
* int val; |
|||
* TreeNode left; |
|||
* TreeNode right; |
|||
* TreeNode(int x) { val = x; } |
|||
* } |
|||
*/ |
|||
class Solution { |
|||
//前序遍历:根节点,左子树的前序遍历,右子树的前序遍历 |
|||
//中序遍历:左子树的中序遍历,根节点,右子树的中序遍历 |
|||
//根据前序遍历,可以方便的找到根节点、左右子树的根节点 |
|||
//根据中序遍历,可以方便的找到左节点、右节点 |
|||
private HashMap<Integer,Integer> hm = new HashMap(); |
|||
private int[] preorder1; |
|||
public TreeNode buildTree(int[] preorder, int[] inorder) { |
|||
preorder1 = preorder; |
|||
//将inorder存储到map中 |
|||
for(int i=0; i<inorder.length; i++){ |
|||
hm.put(inorder[i],i); |
|||
} |
|||
//根据递归函数,求解 |
|||
return recur(0,0,inorder.length-1); |
|||
} |
|||
|
|||
public TreeNode recur(int preRootIndex, int inLeftIndex, int inRightIndex){ |
|||
//递归结束条件 |
|||
if(inLeftIndex > inRightIndex)return null; |
|||
//左子树的根节点 |
|||
int perLeftRootIndex = preRootIndex+1; |
|||
//左子树的左节点不变,inLeftIndex |
|||
//左子树的右节点 |
|||
int inRootIndex = hm.get(preorder1[preRootIndex]); |
|||
int inLeftRightIndex = inRootIndex -1; |
|||
|
|||
//右子树的根节点 |
|||
int perRightRootIndex = inRootIndex - inLeftIndex + preRootIndex + 1; |
|||
//右子树的左节点 |
|||
int perRightLeftIndex = inRootIndex + 1; |
|||
|
|||
//根节点 |
|||
TreeNode treeNode = new TreeNode(preorder1[preRootIndex]); |
|||
//左节点,输入的是左子树的根节点,左子树的左节点,左子树的右节点 |
|||
treeNode.left = recur(perLeftRootIndex, inLeftIndex, inLeftRightIndex); |
|||
//右节点 |
|||
treeNode.right = recur(perRightRootIndex, perRightLeftIndex, inRightIndex); |
|||
|
|||
return treeNode; |
|||
|
|||
} |
|||
} |
|||
``` |
|||
|
|||
# 两个栈实现队列-简单 |
|||
|
|||
用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 ) |
|||
|
|||
|
|||
|
|||
```java |
|||
class CQueue { |
|||
private Stack<Integer> a; |
|||
private Stack<Integer> b ; |
|||
|
|||
public CQueue() { |
|||
a = new Stack<>(); |
|||
b = new Stack<>(); |
|||
} |
|||
|
|||
public void appendTail(int value) { |
|||
a.push(value); |
|||
} |
|||
|
|||
public int deleteHead() { |
|||
if(!b.isEmpty())return b.pop(); |
|||
while(!a.isEmpty()){ |
|||
b.push(a.pop()); |
|||
} |
|||
return b.isEmpty()?-1:b.pop(); |
|||
} |
|||
} |
|||
|
|||
/** |
|||
* Your CQueue object will be instantiated and called as such: |
|||
* CQueue obj = new CQueue(); |
|||
* obj.appendTail(value); |
|||
* int param_2 = obj.deleteHead(); |
|||
*/ |
|||
``` |
|||
|
|||
# 斐波那契数列-简单 |
|||
|
|||
写一个函数,输入 n ,求斐波那契(Fibonacci)数列的第 n 项(即 F(N))。斐波那契数列的定义如下: |
|||
|
|||
``` |
|||
F(0) = 0, F(1) = 1 |
|||
F(N) = F(N - 1) + F(N - 2), 其中 N > 1. |
|||
``` |
|||
|
|||
斐波那契数列由 0 和 1 开始,之后的斐波那契数就是由之前的两数相加而得出。 |
|||
|
|||
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。 |
|||
|
|||
|
|||
```java |
|||
//直接用递归会导致超时 |
|||
//方法1 |
|||
class Solution { |
|||
public int fib(int n) { |
|||
if(n<2) return n; |
|||
int[] fn = new int[n+1]; |
|||
fn[0] = 0; |
|||
fn[1]= 1; |
|||
for(int i =2; i<=n; i++){ |
|||
fn[i]= (fn[i-1] +fn[i-2])%1000000007; |
|||
} |
|||
return fn[n]; |
|||
} |
|||
} |
|||
|
|||
//方法2 记忆化递归 |
|||
class Solution { |
|||
int[] al = new int[101]; |
|||
|
|||
public int fib(int n) { |
|||
if(n<2) return n; |
|||
if(al[n]!=0) return al[n]; |
|||
al[n] =(fib(n-1)+fib(n-2))%1000000007 ; |
|||
|
|||
return al[n]; |
|||
} |
|||
} |
|||
|
|||
//方法三,动态规划 |
|||
class Solution { |
|||
|
|||
public int fib(int n) { |
|||
int a=0; |
|||
int b=1; |
|||
int sum=0; |
|||
if(n<2) return n; |
|||
for(int i = 2; i <= n; i++){ |
|||
sum = (a + b)%1000000007; |
|||
a = b; |
|||
b = sum; |
|||
|
|||
} |
|||
return sum; |
|||
} |
|||
} |
|||
``` |
|||
|
|||
# 青蛙跳台阶问题 |
|||
|
|||
一只青蛙一次可以跳上1级台阶,也可以跳上2级台阶。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。 |
|||
|
|||
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。 |
|||
|
|||
思路:此类求 多少种可能性 的题目一般都有 递推性质 ,即 f(n)f(n) 和 f(n-1)f(n−1)…f(1)f(1) 之间是有联系的。 |
|||
|
|||
设跳上 nn 级台阶有 f(n)f(n) 种跳法。在所有跳法中,青蛙的最后一步只有两种情况: 跳上 11 级或 22 级台阶。 |
|||
当为 11 级台阶: 剩 n-1n−1 个台阶,此情况共有 f(n-1)f(n−1) 种跳法; |
|||
当为 22 级台阶: 剩 n-2n−2 个台阶,此情况共有 f(n-2)f(n−2) 种跳法。 |
|||
f(n)f(n) 为以上两种情况之和,即 f(n)=f(n-1)+f(n-2)f(n)=f(n−1)+f(n−2) ,以上递推性质为斐波那契数列。本题可转化为 求斐波那契数列第 nn 项的值 ,与 斐波那契数列 等价,唯一的不同在于起始数字不同。 |
|||
|
|||
```java |
|||
class Solution { |
|||
public int numWays(int n) { |
|||
if(n<2) return 1; |
|||
int a =1; |
|||
int b = 1; |
|||
int fn = 0; |
|||
for(int i = 2; i<=n; i++){ |
|||
fn = (a + b) % 1000000007; |
|||
a = b; |
|||
b = fn; |
|||
} |
|||
return fn; |
|||
} |
|||
} |
|||
``` |
|||
|
|||
# 旋转数组的最小数字 |
|||
|
|||
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个递增排序的数组的一个旋转,输出旋转数组的最小元素。例如,数组 [3,4,5,1,2] 为 [1,2,3,4,5] 的一个旋转,该数组的最小值为1 |
|||
|
|||
```java |
|||
class Solution { |
|||
public int minArray(int[] numbers) { |
|||
int size = numbers.length; |
|||
int begin = 0; |
|||
int end = size-1; |
|||
int mid = 0; |
|||
while(begin<end){ |
|||
mid = (end + begin)>>1; |
|||
if(numbers[mid]==numbers[end]){ |
|||
end--; |
|||
}else if(numbers[mid]<numbers[end]){ |
|||
end = mid; |
|||
}else{ |
|||
begin = mid+1; |
|||
} |
|||
} |
|||
return numbers[begin]; |
|||
} |
|||
} |
|||
``` |
|||
|
|||
# 矩阵中的路径-中等难度 |
|||
|
|||
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。 |
|||
|
|||
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。 |
|||
|
|||
思路: |
|||
|
|||
本题为**网格、迷宫**类矩阵搜索问题,可使用 深度优先搜索(DFS)+ 剪枝 解决。 |
|||
|
|||
* 深度优先搜索: 可以理解为暴力法遍历矩阵中所有字符串可能性。DFS 通过递归,先朝一个方向搜到底,再回溯至上个节点,沿另一个方向搜索,以此类推。 |
|||
* 剪枝: 在搜索中,遇到 这条路不可能和目标字符串匹配成功 的情况(例如:此矩阵元素和目标字符不同、此元素已被访问),则应立即返回,称之为 可行性剪枝 。 |
|||
|
|||
```java |
|||
class Solution { |
|||
boolean[][] bl; //用来标记是否已经遍历过 |
|||
public boolean exist(char[][] board, String word) { |
|||
char [] words = word.toCharArray(); |
|||
|
|||
for(int i = 0; i < board.length; i++){ |
|||
for(int j = 0; j < board[0].length; j++){ |
|||
if(recur(i, j, 0, board, words)) return true; |
|||
} |
|||
} |
|||
return false; |
|||
} |
|||
|
|||
//i,j为矩阵下表 |
|||
//w为单词下标 |
|||
public boolean recur(int i, int j, int w, char[][]board, char[]words){ |
|||
//越界,结束循环 |
|||
if(i<0||j<0||i>=board.length||j>=board[0].length) return false; |
|||
|
|||
if(board[i][j] != words[w]) {//当前元素不符合,结束循环 |
|||
return false; |
|||
}else if(w == words.length-1){ |
|||
return true; //当单词的最后一个单词已经找到后,结束循环 |
|||
} |
|||
|
|||
//标记该元素已经使用 |
|||
board[i][j] = '\0'; |
|||
|
|||
//向四个方向递归 |
|||
boolean result = recur(i+1, j, w+1, board, words)||recur(i-1, j, w+1, board, words)||recur(i, j+1, w+1, board, words)||recur(i, j-1, w+1, board, words); |
|||
|
|||
//恢复,别的路径会再次对其遍历 |
|||
board[i][j] = words[w]; |
|||
|
|||
return result; |
|||
} |
|||
} |
|||
``` |
|||
|
|||
此题也可以使用方向数组进行向四个方向递归 |
|||
|
|||
在搜索的过程中,假设我们当前到达了b[i][j],那么此时我们需要去判断四周的四个方格是否满足条件 |
|||
这时就可以使用方向数组 |
|||
|
|||
```java |
|||
//定义两个数组 dx代表方向的第一维,dy代表方向的第二维 |
|||
int[] dx = {0, 1, 0, -1}, dy = {1, 0, -1, 0}; |
|||
int x = i + dx[d], y = j + dy[d]; |
|||
//当d = 0时,(x,y)就相当于(i,j)坐标往右走了一格的坐标 |
|||
//同样的,当d = 1,2,3时,分别代表向下,向左,向上走一格 |
|||
``` |
|||
|
|||
# 机器人的运动范围 |
|||
|
|||
地上有一个m行n列的方格,从坐标 [0,0] 到坐标 [m-1,n-1] 。一个机器人从坐标 [0, 0] 的格子开始移动,它每次可以向左、右、上、下移动一格(不能移动到方格外),也不能进入行坐标和列坐标的数位之和大于k的格子。例如,当k为18时,机器人能够进入方格 [35, 37] ,因为3+5+3+7=18。但它不能进入方格 [35, 38],因为3+5+3+8=19。请问该机器人能够到达多少个格子? |
|||
|
|||
```java |
|||
class Solution { |
|||
//深度优先搜索DFS |
|||
int result = 0; |
|||
public int movingCount(int m, int n, int k) { |
|||
boolean [][] bl = new boolean[m][n]; |
|||
return recur(0, 0, m, n, k, bl); |
|||
|
|||
} |
|||
|
|||
//迭代函数 |
|||
public int recur(int i, int j, int m, int n, int k, boolean [][] bl){ |
|||
//终止条件:1.越界;2.数位之和大于K;3.已经遍历过 |
|||
if(i>=m||j>=n||Sum(i,j)>k||bl[i][j]) return 0; |
|||
|
|||
//设置标记值 |
|||
bl[i][j] = true; |
|||
|
|||
//重复调用 |
|||
result = 1 + recur(i+1, j, m, n, k, bl) +recur(i, j+1, m, n, k, bl); |
|||
|
|||
//返回计数 |
|||
return result; |
|||
} |
|||
|
|||
//计算两个坐标数位之和 |
|||
private int Sum(int m, int n){ |
|||
int sum = 0; |
|||
while(m!=0){ |
|||
sum += m % 10; |
|||
m = m / 10; |
|||
} |
|||
while(n!=0){ |
|||
sum += n % 10; |
|||
n = n / 10; |
|||
} |
|||
return sum; |
|||
} |
|||
} |
|||
``` |
|||
|
|||
```java |
|||
//广度优先搜索bfs |
|||
public int movingCount(int m, int n, int k) { |
|||
//临时变量visited记录格子是否被访问过 |
|||
boolean[][] visited = new boolean[m][n]; |
|||
int res = 0; |
|||
//创建一个队列,保存的是访问到的格子坐标,是个二维数组 |
|||
Queue<int[]> queue = new LinkedList<>(); |
|||
//从左上角坐标[0,0]点开始访问,add方法表示把坐标 |
|||
// 点加入到队列的队尾 |
|||
queue.add(new int[]{0, 0}); |
|||
while (queue.size() > 0) { |
|||
//这里的poll()函数表示的是移除队列头部元素,因为队列 |
|||
// 是先进先出,从尾部添加,从头部移除 |
|||
int[] x = queue.poll(); |
|||
int i = x[0], j = x[1]; |
|||
//i >= m || j >= n是边界条件的判断,k < sum(i, j)判断当前格子坐标是否 |
|||
// 满足条件,visited[i][j]判断这个格子是否被访问过 |
|||
if (i >= m || j >= n || k < sum(i, j) || visited[i][j]) |
|||
continue; |
|||
//标注这个格子被访问过 |
|||
visited[i][j] = true; |
|||
res++; |
|||
//把当前格子右边格子的坐标加入到队列中 |
|||
queue.add(new int[]{i + 1, j}); |
|||
//把当前格子下边格子的坐标加入到队列中 |
|||
queue.add(new int[]{i, j + 1}); |
|||
} |
|||
return res; |
|||
} |
|||
|
|||
//计算两个坐标数字的和 |
|||
private int sum(int i, int j) { |
|||
int sum = 0; |
|||
while (i != 0) { |
|||
sum += i % 10; |
|||
i /= 10; |
|||
} |
|||
while (j != 0) { |
|||
sum += j % 10; |
|||
j /= 10; |
|||
} |
|||
return sum; |
|||
} |
|||
``` |
|||
|
|||
# 合并两个排序的链表-简单 |
|||
|
|||
输入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的 |
|||
|
|||
```java |
|||
/** |
|||
* Definition for singly-linked list. |
|||
* public class ListNode { |
|||
* int val; |
|||
* ListNode next; |
|||
* ListNode(int x) { val = x; } |
|||
* } |
|||
*/ |
|||
|
|||
//迭代法 |
|||
class Solution { |
|||
public ListNode mergeTwoLists(ListNode l1, ListNode l2) { |
|||
//迭代法 |
|||
//初始化头节点 |
|||
ListNode head = new ListNode(); |
|||
ListNode cur = head; |
|||
while(l1!=null && l2 != null){ |
|||
if(l1.val <= l2.val){ |
|||
cur.next = l1; |
|||
l1 = l1.next; |
|||
}else{ |
|||
cur.next = l2; |
|||
l2 = l2.next; |
|||
} |
|||
cur = cur.next; |
|||
} |
|||
|
|||
//判空 |
|||
cur.next = l1 == null ? l2:l1; |
|||
//下一个节点才是头节点 |
|||
return head.next; |
|||
|
|||
} |
|||
} |
|||
//时间复杂度:O(m + n),m和n分别为两链表长度 |
|||
//空间复杂度:O(1) |
|||
|
|||
//递归法 |
|||
class Solution { |
|||
public ListNode mergeTwoLists(ListNode l1, ListNode l2) { |
|||
//递归法 |
|||
//终止条件 |
|||
if(l1 == null || l2 == null){ |
|||
return l1 != null ? l1 : l2; |
|||
} |
|||
|
|||
//迭代 |
|||
if(l1.val <= l2.val){ |
|||
l1.next = mergeTwoLists(l1.next, l2); |
|||
return l1; |
|||
}else{ |
|||
l2.next = mergeTwoLists(l1, l2.next); |
|||
return l2; |
|||
} |
|||
} |
|||
} |
|||
``` |
|||
|
|||
# 左旋转字符串 |
|||
|
|||
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的结果"cdefgab"。 |
|||
|
|||
```java |
|||
//方法1,采用substring |
|||
class Solution { |
|||
public String reverseLeftWords(String s, int n) { |
|||
//substring 1 |
|||
return s.substring(n, s.length())+s.substring(0,n); |
|||
} |
|||
} |
|||
|
|||
//方法2,方法1的进阶版 |
|||
class Solution { |
|||
public String reverseLeftWords(String s, int n) { |
|||
//substring 2 |
|||
return (s+s).substring(n,n+s.length()); |
|||
} |
|||
} |
|||
|
|||
//方法3,采用StringBuilder遍历拼接,或者直接用string,采用+直接连接s.charAt(i) |
|||
class Solution { |
|||
public String reverseLeftWords(String s, int n) { |
|||
//StringBuilder |
|||
StringBuilder sb = new StringBuilder(); |
|||
for(int i=n; i<s.length(); i++){ |
|||
sb.append(s.charAt(i)); |
|||
} |
|||
for(int i=0; i<n; i++){ |
|||
sb.append(s.charAt(i)); |
|||
} |
|||
return sb.toString(); |
|||
} |
|||
} |
|||
|
|||
//方法4,方法3的进阶版,求余运算 |
|||
class Solution { |
|||
public String reverseLeftWords(String s, int n) { |
|||
//StringBuilder |
|||
StringBuilder sb = new StringBuilder(); |
|||
for(int i=n; i<n+s.length(); i++){ |
|||
sb.append(s.charAt(i%s.length())); |
|||
} |
|||
return sb.toString(); |
|||
} |
|||
} |
|||
|
|||
//方法5,反转数组 |
|||
class Solution { |
|||
public String reverseLeftWords(String s, int n) { |
|||
char [] c = s.toCharArray(); |
|||
//反转全部 |
|||
rever(c, 0, s.length()-1); |
|||
//反转0-n |
|||
rever(c, 0, s.length()-n-1); |
|||
//反转n-s.length() |
|||
rever(c, s.length()-n, s.length()-1); |
|||
return new String(c); |
|||
} |
|||
|
|||
//反转 |
|||
public void rever(char [] c, int start, int end){ |
|||
while(start<end){ |
|||
char temp = c[start]; |
|||
c[start++]=c[end]; |
|||
c[end--]=temp; |
|||
} |
|||
} |
|||
} |
|||
``` |
|||
|
|||
# 二叉树的镜像-简单 |
|||
|
|||
请完成一个函数,输入一个二叉树,该函数输出它的镜像。 |
|||
|
|||
该题主要考察二叉树的遍历; |
|||
|
|||
可以通过多种方式,如中序遍历、前序遍历、后续遍历、递归、BFS、DFS |
|||
|
|||
```java |
|||
/** |
|||
* Definition for a binary tree node. |
|||
* public class TreeNode { |
|||
* int val; |
|||
* TreeNode left; |
|||
* TreeNode right; |
|||
* TreeNode(int x) { val = x; } |
|||
* } |
|||
*/ |
|||
// 递归,可以改编成前中后序遍历 |
|||
class Solution { |
|||
public TreeNode mirrorTree(TreeNode root) { |
|||
//递归 |
|||
//终止条件:遍历节点为空 |
|||
if(root == null){ |
|||
return null; |
|||
} |
|||
|
|||
//交换 |
|||
TreeNode temp = mirrorTree(root.left); |
|||
root.left = mirrorTree(root.right); |
|||
root.right = temp; |
|||
return root; |
|||
} |
|||
} |
|||
|
|||
//BFS |
|||
class Solution { |
|||
public TreeNode mirrorTree(TreeNode root) { |
|||
//BFS搜索 |
|||
if(root == null) return null; |
|||
Queue<TreeNode> al = new LinkedList<>(); |
|||
al.add(root); |
|||
while(!al.isEmpty()){ |
|||
TreeNode node = al.poll(); |
|||
TreeNode temp = node.left; |
|||
node.left = node.right; |
|||
node.right = temp; |
|||
if(node.left!=null){ |
|||
al.add(node.left); |
|||
} |
|||
if(node.right!=null){ |
|||
al.add(node.right); |
|||
} |
|||
} |
|||
return root; |
|||
} |
|||
} |
|||
|
|||
|
|||
//DFS 费时 前序遍历 |
|||
class Solution { |
|||
public TreeNode mirrorTree(TreeNode root) { |
|||
//DFS搜索 |
|||
if(root == null) return null; |
|||
Stack<TreeNode> al = new Stack<>(); |
|||
al.push(root); |
|||
while(!al.isEmpty()){ |
|||
TreeNode node = al.pop(); |
|||
TreeNode temp = node.left; |
|||
node.left = node.right; |
|||
node.right = temp; |
|||
if(node.right!=null){ |
|||
al.add(node.right); |
|||
} |
|||
if(node.left!=null){ |
|||
al.add(node.left); |
|||
} |
|||
} |
|||
return root; |
|||
} |
|||
} |
|||
|
|||
//中序遍历 |
|||
class Solution { |
|||
public TreeNode mirrorTree(TreeNode root) { |
|||
//中序遍历 |
|||
if(root == null) return null; |
|||
Stack<TreeNode> stack = new Stack<>(); |
|||
TreeNode node = root; |
|||
while(node != null || !stack.isEmpty()){ |
|||
while(node!=null){ |
|||
stack.push(node); |
|||
node = node.left; |
|||
} |
|||
if(!stack.isEmpty()){ |
|||
node = stack.pop(); |
|||
TreeNode temp = node.left; |
|||
node.left = node.right; |
|||
node.right = temp; |
|||
node = node.left; |
|||
} |
|||
} |
|||
return root; |
|||
} |
|||
} |
|||
|
|||
``` |
|||
|
|||
|
|||
|
|||
@ -0,0 +1,735 @@ |
|||
--- |
|||
title: 数据结构和算法-未完成 |
|||
author: TianZD |
|||
top: true |
|||
cover: true |
|||
toc: true |
|||
mathjax: false |
|||
summary: 基于Java的数据结构和算法,未完成,粗略学了一下,没有参考价值 |
|||
tags: |
|||
- 数据结构 |
|||
- 算法 |
|||
categories: |
|||
- java |
|||
- 数据结构和算法 |
|||
reprintPolicy: cc_by |
|||
abbrlink: b1f89a38 |
|||
date: 2022-04-29 10:42:56 |
|||
coverImg: |
|||
img: |
|||
password: |
|||
--- |
|||
|
|||
|
|||
|
|||
[TOC] |
|||
|
|||
> 概述:学习《漫画算法:小灰的算法之旅》 |
|||
|
|||
# 1、数据结构基础 |
|||
|
|||
## 1.1、数据结构分类 |
|||
|
|||
>数据结构是以某种特定的布局方式可存储数据的容器,布局方式决定了数据结构对于某些操作是高效的,对于其他操作是低效的。 |
|||
|
|||
数据结构 = 逻辑结构+物理结构(顺序、链式、索引、散列) |
|||
|
|||
* 逻辑结构 |
|||
* 线性结构:顺序表、栈、队列 |
|||
* 非线性结构:树、图 |
|||
|
|||
* 物理结构:(存储结构),在计算机存储器中的存储形式 |
|||
* 顺序存储结构:数组 |
|||
* 链式存储结构:链表 |
|||
|
|||
逻辑分类: |
|||
|
|||
1. 线性结构:结构中的元素存在一对一的相互关系(元素之间有序,一个挨一个),常见的有:线性表、栈、队列、串(一维数组); |
|||
2. 树形结构:元素存在一对多的相互关系;常见的有:二叉树、红黑树、B树、哈夫曼树等; |
|||
3. 图形结构:元素存在多对多的关系;常见:有向图、无向图、简单图; |
|||
|
|||
## 1.2、数组 |
|||
|
|||
### 概述 |
|||
|
|||
* 有限个相同类型的变量组成的有序集合 |
|||
* 物理结构:**顺序存储结构**,在内存中顺序存储 |
|||
* 逻辑结构:**线性结构** |
|||
|
|||
### 基本操作 |
|||
|
|||
> 读取元素 |
|||
|
|||
可以直接通过下标进行随机读取,时间复杂度O(1) |
|||
|
|||
> 更新元素 |
|||
|
|||
通过下标直接进行赋值替换,时间复杂度O(1) |
|||
|
|||
> 插入元素 |
|||
|
|||
涉及到元素的移动,时间复杂度O(n) |
|||
|
|||
* 尾部插入 |
|||
|
|||
* 中间插入 |
|||
|
|||
* 超范围插入(扩容) |
|||
|
|||
> 删除元素 |
|||
|
|||
和插入相反,时间复杂度O(n) |
|||
|
|||
### 优劣势 |
|||
|
|||
优点: |
|||
|
|||
* 数据访问:可以通过下标进行,效率高 |
|||
|
|||
缺点: |
|||
|
|||
* 插入删除:在内存中采用顺序存储,插入和删除导致大量元素移动,效率低 |
|||
|
|||
总结:适用于**读操作多、写操作少**的场景 |
|||
|
|||
## 1.3、链表 |
|||
|
|||
### 概述 |
|||
|
|||
* 分为单向链表和双向链表 |
|||
* 物理上非连续、非顺序,在内存中**随机存储** |
|||
* 由若干节点**node**组成 |
|||
* 物理结构:**链式存储结构** |
|||
* 逻辑结构:**线性结构** |
|||
|
|||
> 单向链表 |
|||
|
|||
每一个node包含两个属性: |
|||
|
|||
* data:存放数据的变量 |
|||
* node节点指针next:指向下一个节点 |
|||
|
|||
```java |
|||
private static class Node{ |
|||
int data; |
|||
Node next; |
|||
} |
|||
``` |
|||
|
|||
单向链表只能通过next指针找到关联的下一个节点,逐一寻找,只需要知道第一个节点,便可以根据找到所有的节点,因此用第一个节点标识链表,单向链表的第一个节点又称为**头节点** |
|||
|
|||
头尾节点: |
|||
|
|||
* 头节点Head:链表的第一个节点 |
|||
* 尾节点:链表的最后一个节点,next指针指向空,null |
|||
|
|||
> 双向链表 |
|||
|
|||
双向链表每一个node包含三个属性: |
|||
|
|||
* data |
|||
* node节点指针next |
|||
* **node节点指针prev:指向前一个节点** |
|||
|
|||
### 基本操作 |
|||
|
|||
> 查找节点 |
|||
|
|||
从头节点开始,向后逐一查找,时间复杂度O(n) |
|||
|
|||
> 更新节点 |
|||
|
|||
找到后直接将node节点数据进行替换,查找时间复杂度O(n),替换复杂度O(1) |
|||
|
|||
> 插入节点 |
|||
|
|||
如果不考虑查找元素的过程,时间复杂度O(1) |
|||
|
|||
* 尾部插入 |
|||
|
|||
将尾节点的next指针指向新节点 |
|||
|
|||
* 头部插入 |
|||
|
|||
1.把新节点的next指向原来的头节点 |
|||
|
|||
2.把新节点变为头节点 |
|||
|
|||
* 中间插入 |
|||
|
|||
1.将新节点的next指向插入位置的节点 |
|||
|
|||
2.将插入位置前的节点的next指向新节点 |
|||
|
|||
> 删除元素 |
|||
|
|||
如果不考虑查找元素的过程,时间复杂度O(1) |
|||
|
|||
* 尾部删除 |
|||
|
|||
把倒数第二个node的next指向空 |
|||
|
|||
* 头部删除 |
|||
|
|||
把链表的头节点设为原来的第二个节点 |
|||
|
|||
* 中间删除 |
|||
|
|||
把要删除节点的前一个节点的next指向后一个节点 |
|||
|
|||
### 优劣势 |
|||
|
|||
优势: |
|||
|
|||
* 在于能够灵活地进行插入和删除操作 |
|||
|
|||
劣势: |
|||
|
|||
* 查找需要从头部开始逐一遍历 |
|||
|
|||
## 1.4、栈 |
|||
|
|||
### 概述 |
|||
|
|||
* 逻辑结构:**线性存储结构** |
|||
* 物理结构:可以用数组实现也可以用链表 |
|||
* 先入后出FILO |
|||
* 栈顶:最后进入元素的位置 |
|||
* 栈底:最先进入元素的位置 |
|||
|
|||
### 基本操作 |
|||
|
|||
> 入栈push |
|||
|
|||
把新元素放入栈中,只能从栈顶放入,作为新的栈顶 |
|||
|
|||
时间复杂度O(1) |
|||
|
|||
> 出栈pop |
|||
|
|||
把元素弹出,只能弹出栈顶元素 |
|||
|
|||
时间复杂度O(1) |
|||
|
|||
### 应用 |
|||
|
|||
输出顺序和输入顺序相反,通常用于对“历史”的回溯 |
|||
|
|||
* 代替递归 |
|||
* 面包屑导航(浏览页面) |
|||
|
|||
## 1.5、队列 |
|||
|
|||
### 概述 |
|||
|
|||
* 逻辑结构:**线性存储结构** |
|||
* 物理结构:可以用数组实现也可以用链表 |
|||
* 先入先出FIFO |
|||
* 对头front |
|||
* 对尾rear |
|||
|
|||
### 基本操作 |
|||
|
|||
> 入队enqueue |
|||
|
|||
把新元素放入队尾 |
|||
|
|||
时间复杂度O(1) |
|||
|
|||
> 出队dequeue |
|||
|
|||
把对头元素移出队列 |
|||
|
|||
时间复杂度O(1) |
|||
|
|||
> 循环队列 |
|||
|
|||
数组实现的队列为了防止出队时,对头左边的空间失去作用,可以采用循环队列的方式维持队列容量的恒定 |
|||
|
|||
* 入队: |
|||
* 队列满:`(rear+1)%array.length==front` |
|||
* `rear=(rear+1)%array.length;` |
|||
* 出队: |
|||
* 队列空:`rear==front` |
|||
* `front=(front+1)%array.length;` |
|||
|
|||
### 应用 |
|||
|
|||
输出顺序和输入顺序相同,用于对历史的回放 |
|||
|
|||
* 多线程中争夺锁 |
|||
* 网络爬虫抓取 |
|||
|
|||
## 1.6、散列表(哈希表) |
|||
|
|||
### 概述 |
|||
|
|||
* 散列表提供了**键(key)** 和**值(value)**的映射关系,可以根据key快速找到对应的value,时间复杂度接近O(1) |
|||
* 本质上是**数组** |
|||
* **通过哈希函数将key转换为数组中的下标** |
|||
|
|||
### 哈希函数 |
|||
|
|||
> hashcode |
|||
|
|||
在java等面向对象的语言中,每一个对象都有自己的**hashcode**,hashcode是区分不同对象的重要标识,不论对象的类型是什么,hashcode都是一个**整型变量** |
|||
|
|||
> 转化 |
|||
|
|||
通常采用hashcode对数组长度的**取模运算** |
|||
|
|||
`index = HashCode(key) % Array.length` |
|||
|
|||
java中的哈希函数采用的是**位运算**的方式,将数组长度取为2的次方,提高性能。 |
|||
|
|||
### 基本操作 |
|||
|
|||
> 写操作 |
|||
|
|||
1. 通过哈希函数,将key转化为数组下标 |
|||
2. 放入元素 |
|||
1. 如果对应的下标没有元素,直接放入 |
|||
2. 如果已有元素,产生**哈希冲突** |
|||
|
|||
哈希冲突解决: |
|||
|
|||
* **开放寻址法**:已有元素时,`index++`,放入下一个,直至对应的下标没有元素占用,ThreadLocal采用 |
|||
* **链表法**:**HashMap采用**,其数组中的每一个元素对应链表的一个节点,最先放入的为头节点,后续放入的通过将上一个节点的next指向该元素,插入到链表中 |
|||
|
|||
> 读操作 |
|||
|
|||
1. 通过哈希函数,将key转化为数组下标 |
|||
2. 找到对应下标对应的元素 |
|||
1. 如果只有一个,则找到 |
|||
2. 如果对应的链表,遍历链表,**直到key值对应** |
|||
|
|||
> 扩容 |
|||
|
|||
当多次插入后,key映射位置发生冲突的概率提高,大量元素拥挤在相同的位置,形成链表很长,导致查询和写入效率低下 |
|||
|
|||
条件: |
|||
|
|||
`HashMap.Size >= Capacity * LoadFactor` |
|||
|
|||
**步骤**: |
|||
|
|||
* **扩容**:新建一个空数组,长度为两倍 |
|||
* **重新Hash**:数组长度变化,需要重新根据哈希函数计算哈希值 |
|||
|
|||
## 1.7、树和二叉树 |
|||
|
|||
### 概述 |
|||
|
|||
> 树 |
|||
|
|||
* 逻辑结构:非线性结构 |
|||
|
|||
> 二叉树 |
|||
|
|||
|
|||
|
|||
### 二叉树应用 |
|||
|
|||
> 查找 |
|||
|
|||
|
|||
|
|||
> 维持相对顺序 |
|||
|
|||
### 二叉树遍历 |
|||
|
|||
从节点位置: |
|||
|
|||
* **前序遍历** |
|||
* **中序遍历** |
|||
* **后序遍历** |
|||
* **层序遍历** |
|||
|
|||
从宏观角度: |
|||
|
|||
* **深度优先遍历:前序、中序、后序** |
|||
* **广度优先遍历:层序** |
|||
|
|||
> 深度优先遍历 |
|||
|
|||
|
|||
|
|||
> 广度优先遍历 |
|||
|
|||
|
|||
|
|||
## 1.8、二叉堆 |
|||
|
|||
### 概述 |
|||
|
|||
* 最大堆 |
|||
* 最小堆 |
|||
|
|||
### 自我调整 |
|||
|
|||
|
|||
|
|||
> 插入 |
|||
|
|||
|
|||
|
|||
> 删除 |
|||
|
|||
|
|||
|
|||
> 构建 |
|||
|
|||
|
|||
|
|||
> 代码 |
|||
|
|||
|
|||
|
|||
## 1.9、优先队列 |
|||
|
|||
### 概述 |
|||
|
|||
|
|||
|
|||
### 实现 |
|||
|
|||
|
|||
|
|||
# 2、排序算法 |
|||
|
|||
## 2.1、分类 |
|||
|
|||
|
|||
|
|||
## 2.2、冒泡排序 |
|||
|
|||
### 基本冒泡排序 |
|||
|
|||
交换排序,两两比较,两层循环,第一层为遍历的轮数:`array.length-1` |
|||
|
|||
时间复杂度O(n^2) |
|||
|
|||
### 优化冒泡排序 |
|||
|
|||
> 第一轮 |
|||
|
|||
防止数列已经有序后仍然进行下一轮排序 |
|||
|
|||
如{5,8,6,3,9,2,1,7} |
|||
|
|||
> 第二轮 |
|||
|
|||
现有逻辑:从`for(int j=0;j<array.length-1;i++)`可以看出有序区的长度为以进行排序的轮数`i` |
|||
|
|||
当后面大部分已经有序后,仍然会进行比较,对此进行优化 |
|||
|
|||
如{3,4,2,1,5,6,7,8} |
|||
|
|||
### 鸡尾酒排序 |
|||
|
|||
双向交换,奇数轮从左向右,偶数轮从右向左 |
|||
|
|||
解决大部分已经有序的情况,如{2,3,4,5,6,7,8,1} |
|||
|
|||
## 2.3、快速排序 |
|||
|
|||
### 概述 |
|||
|
|||
核心:**分治思想** |
|||
|
|||
选定基准元素,大的放右边,小的放左边,一分为2 |
|||
|
|||
时间复杂度O(nlogn) |
|||
|
|||
### 基准元素选择 |
|||
|
|||
* 默认数列的第一个元素 |
|||
* 可以随机选择一个元素作为基准,然后和首元素交换位置 |
|||
|
|||
### 元素交换 |
|||
|
|||
> 双边循环法 |
|||
|
|||
* 基准元素pivot |
|||
* 左指针left |
|||
* 右指针right |
|||
|
|||
> 单边循环法 |
|||
|
|||
* 基准元素pivot |
|||
* 元素区域边界mark |
|||
|
|||
### 递归、非递归实现 |
|||
|
|||
|
|||
|
|||
|
|||
|
|||
## 2.4、堆排序 |
|||
|
|||
|
|||
|
|||
## 2.5、计数排序和桶排序 |
|||
|
|||
|
|||
|
|||
|
|||
|
|||
## 2.6、排序算法复杂度分析 |
|||
|
|||
| 排序算法 | 平均时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 是否稳定 | |
|||
| ---------- | -------------- | -------------- | ---------- | -------- | |
|||
| 冒泡排序 | O(n^2) | O(n^2) | O(1) | 稳定 | |
|||
| 鸡尾酒排序 | O(n^2) | O(n^2) | O(1) | 稳定 | |
|||
| 快速排序 | O(nlogn) | O(n^2) | O(logn) | 不稳定 | |
|||
| 堆排序 | O(nlogn) | O(nlogn) | O(1) | 不稳定 | |
|||
| 计数排序 | O(n+m) | O(n+m) | O(m) | 稳定 | |
|||
| 桶排序 | O(n) | O(nlogn) | O(n) | 稳定 | |
|||
|
|||
# 3、面试算法 |
|||
|
|||
## 3.1、判断链表是否有环 |
|||
|
|||
### 基础版 |
|||
|
|||
> 问题 |
|||
|
|||
如何判断一个链表是否有环 |
|||
|
|||
> 思路 |
|||
|
|||
链表若有环,两个指针分别不同速度,速度快的会追上速度慢的 |
|||
|
|||
* 两个指针指向头节点:`Node p1 = head; Node p2 = head;` |
|||
* p1每次移动一个位置:`p1=p1.next;` |
|||
* p2每次移动两个位置`p2=p2.next.next;` |
|||
* p1和p2相遇则有环:`p1==p2` |
|||
|
|||
> 代码 |
|||
|
|||
|
|||
|
|||
### 扩展 |
|||
|
|||
> 问题 |
|||
|
|||
若有环,求环的长度和入环节点 |
|||
|
|||
> 思路 |
|||
|
|||
**环的长度**:p1和p2的速度相差1,因此二次相遇之间走过的步数就是环的长度 |
|||
|
|||
**入环节点**:通过数学计算可以得到,入环点到头节点的距离==首次相遇点到入环点之间的距离,因此首次相遇后,把一个指针重新指向头节点,两个指针同时一次走一步,再次相遇的点就是入环节点 |
|||
|
|||
## 3.2、最小栈 |
|||
|
|||
> 问题 |
|||
|
|||
实现一个栈,有出栈、入栈,另外要有取最小值方法,同时三个方法的时间复杂度都为O(1) |
|||
|
|||
> 思路 |
|||
|
|||
|
|||
|
|||
> 代码 |
|||
|
|||
|
|||
|
|||
## 3.3、求最大公约数 |
|||
|
|||
> 问题 |
|||
|
|||
求两个整数的最大公约数 |
|||
|
|||
> 思路 |
|||
|
|||
**辗转相除法(欧几里得算法)**:两个正整数a和b(a>b)的最大公约数等于a除以b的余数c和b之间的最大公约数 |
|||
|
|||
**更相减损法**:两个正整数a和b(a>b)的最大公约数等于a-b的差值c和b之间的最大公约数 |
|||
|
|||
> 代码 |
|||
|
|||
|
|||
|
|||
> 优化 |
|||
|
|||
位运算 |
|||
|
|||
|
|||
|
|||
## 3.4、判断一个数是否是2的整数次幂 |
|||
|
|||
> 问题 |
|||
|
|||
判断一个数是否是2的整数次幂 |
|||
|
|||
> 思路 |
|||
|
|||
* 2的整数次幂装换位二进制时,首位为1,其余位为0 |
|||
* 2的整数次幂减去1,转换为二进制时,全部为1,首位为0 |
|||
* 与运算& |
|||
|
|||
> 代码 |
|||
|
|||
|
|||
|
|||
## 3.5、无序数组排序后的最大相邻差 |
|||
|
|||
> 问题 |
|||
|
|||
求出数组排序后的任意两个相邻元素的最大差值 |
|||
|
|||
> 思路 |
|||
|
|||
采用桶排序的思想, |
|||
|
|||
* 分桶 |
|||
* 入桶,记录每一个桶的最大值和最小值 |
|||
* 统计相邻两个桶的最大值和最小值的差 |
|||
|
|||
> 代码 |
|||
|
|||
|
|||
|
|||
## 3.6、用栈实现队列 |
|||
|
|||
> 问题 |
|||
|
|||
用栈模拟队列,实现:入队、出队 |
|||
|
|||
> 思路 |
|||
|
|||
* 两个栈A和B |
|||
* 入队在A中压栈 |
|||
* 出队 |
|||
* B是否为空,空的话首先将A中的元素弹出到B中 |
|||
* B弹栈 |
|||
|
|||
> 代码 |
|||
|
|||
|
|||
|
|||
## 3.7、寻找全排列的下一个数 |
|||
|
|||
> 问题 |
|||
|
|||
给一个正整数,找出全排列的下一个数 |
|||
|
|||
用这个数包含的全部数字重新排列,找出一个大于且仅大于原数的新整数 |
|||
|
|||
> 思路 |
|||
|
|||
固定的几个数字进行排列,逆序排列时数字最大,顺序排列时数字最小,同时为了保持重新排列的数仅比原数大,要尽可能保持高位不变,仅仅改变低位的数字 |
|||
|
|||
* 从后找,找到当前整数的逆序区域(逆序区域已经是最大的了,要找到不是逆序区域的数字的位置),如12354,只变换5和4不能满足比原数大,要从3开始变 |
|||
* 更换找到的位置的数字和最末尾数字,变为12435 |
|||
* 把逆序区域变为顺序,即交换5和4,保持最小 |
|||
|
|||
> 代码 |
|||
|
|||
|
|||
|
|||
## 3.9、删除k个数字后的最小值 |
|||
|
|||
> 问题 |
|||
|
|||
给一个整数,删除k个数字,要求剩下的数字尽可能小 |
|||
|
|||
> 思路 |
|||
|
|||
删除掉一个数字后,整数的位数减少1 |
|||
|
|||
需要从高位起,若该位置数字比后一位大,则需要去掉 |
|||
|
|||
> 代码 |
|||
|
|||
|
|||
|
|||
## 3.9、实现大整数相加 |
|||
|
|||
> 问题 |
|||
|
|||
实现两个很大的整数相加 |
|||
|
|||
> 思路 |
|||
|
|||
根据手动相加思路,低位相加,大于10后,高位加1 |
|||
|
|||
* 数字逆序存到两个数组中 |
|||
* 遍历,若两个数组对应的位置值相加大于10,则保留个位,且高位加1 |
|||
* 下一位相加,同时要加上低位进的1 |
|||
|
|||
> 代码 |
|||
|
|||
|
|||
|
|||
## 3.10、金矿问题 |
|||
|
|||
> 问题 |
|||
|
|||
10名工人,5堆金矿,价值{500,400,350,300,200},需要人力{5,5,3,4,3} |
|||
|
|||
求解如何最大收益 |
|||
|
|||
> 思路 |
|||
|
|||
动态规划 |
|||
|
|||
|
|||
|
|||
> 代码 |
|||
|
|||
|
|||
|
|||
## 3.11、寻找缺失的整数 |
|||
|
|||
### 基本问题 |
|||
|
|||
> 问题 |
|||
|
|||
一个无序数组,有99个不重复的正整数,范围1-100,求出100中缺少的那个 |
|||
|
|||
> 思路 |
|||
|
|||
先计算累加和,然后减去有的99个数,得到的即为缺少的 |
|||
|
|||
### 扩展1 |
|||
|
|||
> 问题 |
|||
|
|||
数量若干,同时99个整数出现了偶数次,1个出现了奇数次,求出这一个数 |
|||
|
|||
> 思路 |
|||
|
|||
异或运算 |
|||
|
|||
### 扩展2 |
|||
|
|||
> 问题 |
|||
|
|||
2个数字出现了奇数次,求这两个数 |
|||
|
|||
> 思路 |
|||
|
|||
分治法 |
|||
|
|||
# 4、算法的应用 |
|||
|
|||
## 4.1、Bitmap |
|||
|
|||
|
|||
|
|||
## 4.2、LRU |
|||
|
|||
|
|||
|
|||
## 4.3、A星寻路算法 |
|||
|
|||
|
|||
|
|||
## 4.4、红包算法 |
|||
|
|||
|
|||
|
|||
|
|||
|
|||
@ -0,0 +1,535 @@ |
|||
--- |
|||
title: 网络编程 |
|||
author: TianZD |
|||
top: true |
|||
cover: true |
|||
toc: true |
|||
mathjax: false |
|||
summary: 网络通信模型、tcp、udp编程学习 |
|||
tags: |
|||
- 网络编程 |
|||
- TCP |
|||
- UDP |
|||
categories: |
|||
- java |
|||
- 网络编程 |
|||
reprintPolicy: cc_by |
|||
abbrlink: f6491cfb |
|||
date: 2022-04-29 11:01:29 |
|||
coverImg: |
|||
img: |
|||
password: |
|||
--- |
|||
|
|||
|
|||
|
|||
[toc] |
|||
|
|||
# 网络基础 |
|||
|
|||
## 网络编程的目的 |
|||
|
|||
直接或间接地通过网络协议与其他计算机实现数据交换,进行通讯 |
|||
|
|||
## 网络编程中两个主要问题 |
|||
|
|||
* 如何准确地定位网络上一台或多台主机,定位主机上的特定应用 |
|||
* 找到住后如何可靠高效地进行数据传输 |
|||
|
|||
## 网络层级 |
|||
|
|||
了使不同计算机厂家生产的计算机能够相互通信,以便在更大的范围内建立计算机网络,国际标准化组织(ISO)在1978年提出了“开放系统互联参考模型”,即著名的OSI/RM模型(Open System Interconnection/Reference [Model](https://so.csdn.net/so/search?q=Model&spm=1001.2101.3001.7020))。它将计算机网络体系结构的通信协议划分为七层,自下而上依次为:物理层(Physics Layer)、数据链路层(Data Link Layer)、网络层(Network Layer)、传输层(Transport Layer)、会话层(Session Layer)、表示层(Presentation Layer)、应用层(Application Layer)。其中第四层完成数据传送服务,上面三层面向用户。 |
|||
|
|||
除了标准的OSI七层模型以外,常见的[网络层](https://so.csdn.net/so/search?q=网络层&spm=1001.2101.3001.7020)次划分还有TCP/IP四层协议以及TCP/IP五层协议,它们之间的对应关系如下图所示: |
|||
|
|||
 |
|||
|
|||
 |
|||
|
|||
**应用层:** |
|||
Message |
|||
|
|||
**传输层:** |
|||
Message+源端口+目的端口 |
|||
|
|||
**网络层:** |
|||
Message+源端口+目的端口+源IP地址+目的IP地址 |
|||
|
|||
**数据链路层:** |
|||
Message+源端口+目的端口+源IP地址+目的IP地址+源MAC地址+目的MAC地址 |
|||
|
|||
**物理层:** |
|||
1、负责传输0和1这样的物理信号 |
|||
|
|||
|
|||
|
|||
| 协议层 | 关键元素 | 作用 | |
|||
| ---------- | -------------- | -------------------------------------------------------- | |
|||
| 数据链路层 | MAC地址 | 依靠MAC地址,构建同子网主机到主机的数据包传输链路 | |
|||
| 网络层 | IP地址 | 依靠IP地址,构建源子网到目标子网的数据包传输链路 | |
|||
| 传输层 | 端口 | 依靠端口,构建源进程到目标进程的传输链路 | |
|||
| 应用层 | 应用自定义规则 | 依靠客户端与服务端共同定义的规则完成客户端与服务端的交互 | |
|||
|
|||
从“看”的角度----传输层、网络层、数据链路层的内容是一堆不容易看懂的十六进制数;而应用层是一些可读的字符串 |
|||
|
|||
从“写”的角度----在手动构造MAC头/IP头/TCP头时,一个IP、一个端口要进行半天的转换和拼接;而应用层都是string+=xxxx就完事了 |
|||
|
|||
简单而言造成这个问题的原因是:传输层/网络层/数据链路层的内容多用二进制代号或者数值类型,而应用层使用的是ASCII码。 |
|||
|
|||
|
|||
|
|||
按照OSI的模型,上层利用相邻下层的服务,与通信对端的同一层建立对等的服务,最高一层叫**应用层**,最下一层叫**物理层**。 |
|||
比如你说你要告诉你的朋友,你的兰花开了,“兰花开了”是一条信息,是“**应用层**”需要传递的。你可以选择传递一句话,或者一张照片,将信息“表示为”一串数字或者物理实体,这是“**表示层**”该干的。如果你选择把这件事写在纸上交给对方,你得了解对方不是盲人、不是文盲、懂你写下的语言(比如中文),这是你选择**表示层**时候必须考虑的。你可以与对方成文或不成文的约定你们采用的语言,这叫**协议**。 |
|||
确定了表示方法,你就需要选择把这个东西传给谁,怎么传。这次信息传送是孤立的,还是一大串信息传递(比如笔友还是生意往来)中的一部分。这叫**会话**。 |
|||
确定了会话,你要确定怎么找到你的朋友。你的朋友,大明王二三,小名三仔,昵称二子,俗称二三娃,网名3123,是王一万的儿子,是A公司职员,住在B地址,是C群体的会员,每个称呼都代表着不同的**传输方法**,成本、速度、可靠性都不同,你选哪一个?选择不同,你就需要和不同的中间人说一些不同的话,最终目的是把那一串数字或者物理实体传递给正确的人。这叫**传输层**。 |
|||
如果表示方法是一张照片,打算通过邮局邮寄给你的朋友,相应的会话层确定是单次通信,传输层的工作就是找到一个信封,把照片放在里面,封上封口,在信封上写上地址和名字。你必须找到你的朋友的邮寄地址。有了地址和你朋友的名字,你就试着用**会话层**提供的服务。地址代表着**网络层**的服务,名字代表着**传输层**的服务。虽然OSI的规定上传输层和[网络层](https://so.csdn.net/so/search?q=网络层&spm=1001.2101.3001.7020)互相独立,但是实际上是很难分开的。注意,这里的选项是你决定的,或者说是你和你的通信对象选择的会话方法决定的。你和你的通信对象完全可以另起炉灶约定一种谁也没见过的方法,不会伤害到任何人。你选择了对方地址,写在信封上,将照片装在信封里面不给邮递员看,这叫**封装**。经过封装后,邮政局传送的是信,而不是照片。有些封装(比如明信片)可以被邮递员看到并串改,这在数字世界很不常见。将封装好的新建丢进信筒或者交给快递员,都是你开始使用“**网络层**”服务了。 |
|||
在这个例子里,**邮政局为你提供网络层服务**。一般说来,网络层按照对方地址来决定如何将信息传递到对方。你看,同样的网络层完全可以提供不同的服务,比如平信、快信和专递(当然收费也不同)。IP在这里,你要通过IP网通信,你需要知道对方的IP地址。邮政局不会专门为你把你的信专门送到对方手中,而是通过不同层次的分拣站逐层解析地址逐层传送。在收信局,每封信都要分拣,走同样路径的信件可能会被打成邮包并标记上对方分拣站的地址,这叫**路由**(翻译自route,是个动词,表示寻找路径的意思)。邮局会将“目的地分拣站”相同的信件装在邮包里快速传递,这叫**数据链路层**。数据链路层不需要知道用户信件的最终地址,只按照固定往来路径传送邮包。在OSI语境下,数据链路层可以有地址,但是这个地址只有链路层互联的终端之间有意义,而网络层地址必须是全局(全网)唯一的。往来用户收发信件的邮递员知道你的地址和交通方式,而且只需要记住他负责的片区的信息,如果有片区内的信件往来他可能直接就替你送了(在邮政局是不允许的,对快递员可能会收一点小费后就接受了),这叫**局域网**,是数据链路层的特例。注意,分拣局之间收发邮包的路径(数据链路层)无论是否遵循公开的标准都是邮政局(网络)的选择,不受任何用户干扰,和传输层。干扰邮包收发是犯罪(网络黑客)行为。你是公司职员,为公事发信,信件被前台秘书统一交寄,寄出的信件只有公司的地址和你的名字,收到的信件由前台秘书统一签收,并叫你自取或(如果你和TA关系足够好或职位足够高)送到你的办公桌上,这位秘书就是NAT。无论如何,信件还是邮包,总是装在自行车/卡车/火车/轮船/飞机上运输的,这些运输工具可能属于也可能不属于邮政局,但是总是按照自己的固定路线转运货物,甚至不知道传送的货物中有“邮包”或者“信件”这类东西,这叫**物理层**。如果你们公司是个跨国公司,对内部信件规定了特别的方法,以上所说每一件事都有人干但是并没有严格依照上述方法来传递,这叫**内部网**(PrivateNetwork, Intranet)。有时候还会将自己内部信件打包交给快递公司传送,这叫VPN。最后,按照OSI模型的语境,你不能是人,也不能是狗,甚至不能是计算机,你必须是一台计算机上运行的一个程序。 |
|||
|
|||
网络层具体就是指IP(Internet Protocol),因特网协议,应用层一般有HTTP,FTP等,中间还有个传输层,具体一般是TCP和UDP |
|||
那网络层和应用层是什么关系呢 |
|||
应用层(HTTP)建立在传输层(TCP)基础上,传输层建立在网络层(IP)基础上 |
|||
|
|||
### 物理层 |
|||
|
|||
激活、维持、关闭通信端点之间的机械特性、电气特性、功能特性以及过程特性。**该层为上层协议提供了一个传输数据的可靠的物理媒体。简单的说,物理层确保原始的数据可在各种物理媒体上传输。**物理层记住两个重要的设备名称,中继器(Repeater,也叫放大器)和集线器。 |
|||
|
|||
### 数据链路层 |
|||
|
|||
数据链路层在物理层提供的服务的基础上向网络层提供服务,其最基本的服务是将源自网络层来的数据可靠地传输到相邻节点的目标机网络层。为达到这一目的,数据链路必须具备一系列相应的功能,主要有:如何将数据组合成数据块,在数据链路层中称这种数据块为帧(frame),帧是数据链路层的传送单位;如何控制帧在物理信道上的传输,包括如何处理传输差错,如何调节发送速率以使与接收方相匹配;以及在两个网络实体之间提供数据链路通路的建立、维持和释放的管理。数据链路层在不可靠的物理介质上提供可靠的传输。该层的作用包括:物理地址寻址、数据的成帧、流量控制、数据的检错、重发等。 |
|||
|
|||
有关数据链路层的重要知识点: |
|||
|
|||
**1> 数据链路层为网络层提供可靠的数据传输;** |
|||
|
|||
**2> 基本数据单位为帧;** |
|||
|
|||
**3> 主要的协议:以太网协议;** |
|||
|
|||
**4> 两个重要设备名称:网桥和交换机。** |
|||
|
|||
### 网络层 |
|||
|
|||
网络层的目的是实现两个端系统之间的数据透明传送,具体功能包括寻址和路由选择、连接的建立、保持和终止等。它提供的服务使传输层不需要了解网络中的数据传输和交换技术。如果您想用尽量少的词来记住网络层,那就是“路径选择、路由及逻辑寻址”。 |
|||
|
|||
网络层中涉及众多的协议,其中包括最重要的协议,也是TCP/IP的核心协议——IP协议。IP协议非常简单,仅仅提供不可靠、无连接的传送服务。IP协议的主要功能有:无连接数据报传输、数据报路由选择和差错控制。与IP协议配套使用实现其功能的还有地址解析协议ARP、逆地址解析协议RARP、因特网报文协议ICMP、因特网组管理协议IGMP。具体的协议我们会在接下来的部分进行总结,有关网络层的重点为: |
|||
|
|||
**1> 网络层负责对子网间的数据包进行路由选择。此外,网络层还可以实现拥塞控制、网际互连等功能;** |
|||
|
|||
**2> 基本数据单位为IP数据报;** |
|||
|
|||
**3> 包含的主要协议:** |
|||
|
|||
**IP协议(Internet Protocol,因特网互联协议);** |
|||
|
|||
**ICMP协议(Internet Control Message Protocol,因特网控制报文协议);** |
|||
|
|||
**ARP协议(Address Resolution Protocol,地址解析协议);** |
|||
|
|||
**RARP协议(Reverse Address Resolution Protocol,逆地址解析协议)。** |
|||
|
|||
**4> 重要的设备:路由器。** |
|||
|
|||
### 传输层 |
|||
|
|||
第一个端到端,即主机到主机的层次。传输层负责将上层数据分段并提供端到端的、可靠的或不可靠的传输。此外,传输层还要处理端到端的差错控制和流量控制问题。 |
|||
|
|||
传输层的任务是根据通信子网的特性,最佳的利用网络资源,为两个端系统的会话层之间,提供建立、维护和取消传输连接的功能,负责端到端的可靠数据传输。在这一层,信息传送的协议数据单元称为段或报文。 |
|||
|
|||
网络层只是根据网络地址将源结点发出的数据包传送到目的结点,而传输层则负责将数据可靠地传送到相应的端口。 |
|||
|
|||
有关网络层的重点: |
|||
|
|||
**1> 传输层负责将上层数据分段并提供端到端的、可靠的或不可靠的传输以及端到端的差错控制和流量控制问题;** |
|||
|
|||
**2> 包含的主要协议:TCP协议(Transmission Control Protocol,传输控制协议)、UDP协议(User Datagram Protocol,用户数据报协议);** |
|||
|
|||
**3> 重要设备:网关。** |
|||
|
|||
### 会话层 |
|||
|
|||
会话层管理主机之间的会话进程,即负责建立、管理、终止进程之间的会话。会话层还利用在数据中插入校验点来实现数据的同步 |
|||
|
|||
### 表示层 |
|||
|
|||
表示层对上层数据或信息进行变换以保证一个主机应用层信息可以被另一个主机的应用程序理解。表示层的数据转换包括数据的加密、压缩、格式转换等。 |
|||
|
|||
### 应用层 |
|||
|
|||
为操作系统或网络应用程序提供访问网络服务的接口。 |
|||
|
|||
会话层、表示层和应用层重点: |
|||
|
|||
**1> 数据传输基本单位为报文;** |
|||
|
|||
**2> 包含的主要协议:FTP(文件传送协议)、Telnet(远程登录协议)、DNS(域名解析协议)、SMTP(邮件传送协议),POP3协议(邮局协议),HTTP协议(Hyper Text Transfer Protocol)。** |
|||
|
|||
## Socket |
|||
|
|||
> **socket 其实就是操作系统提供给程序员操作「网络协议栈」的接口,说人话就是,你能通过socket 的接口,来控制协议找工作,从而实现网络通信,达到跨主机通信。** |
|||
|
|||
socket 一般分为 **TCP 网络编程**和 **UDP 网络编程。** |
|||
|
|||
### TCP网络编程 |
|||
|
|||
 |
|||
|
|||
基于 TCP 协议的客户端和服务器工作 |
|||
|
|||
- 服务端和客户端初始化 `socket`,得到文件描述符; |
|||
- 服务端调用 `bind`,将绑定在 IP 地址和端口; |
|||
- 服务端调用 `listen`,进行监听; |
|||
- 服务端调用 `accept`,等待客户端连接; |
|||
- 客户端调用 `connect`,向服务器端的地址和端口发起连接请求; |
|||
- 服务端 `accept` 返回用于传输的 `socket` 的文件描述符; |
|||
- 客户端调用 `write` 写入数据;服务端调用 `read` 读取数据; |
|||
- 客户端断开连接时,会调用 `close`,那么服务端 `read` 读取数据的时候,就会读取到了 `EOF`,待处理完数据后,服务端调用 `close`,表示连接关闭。 |
|||
|
|||
这里需要注意的是,服务端调用 `accept` 时,连接成功了会返回一个已完成连接的 socket,后续用来传输数据。 |
|||
|
|||
所以,监听的 socket 和真正用来传送数据的 socket,是「两个」 socket,一个叫作**监听 socket**,一个叫作**已完成连接 socket**。 |
|||
|
|||
成功连接建立之后,双方开始通过 read 和 write 函数来读写数据,就像往一个文件流里面写东西一样。 |
|||
|
|||
|
|||
|
|||
# 网络通信要素 |
|||
|
|||
1. 通信双方地址 |
|||
* IP |
|||
* 端口 |
|||
2. 一定的规则(网络通信协议) |
|||
* OSI参考模型:模型过于理想化,分为七层:应用层、表示层、会话层、传输层、网络层、数据链路层、物理层 |
|||
* TCP/IP参考模型(TCP/IP协议),分为:应用层(HTTP、FTP、Telnet、DNS等协议)、传输层(TCP、UDP等协议)、网络层(IP、ICMP、ARP等协议)、物理+数据链路层(Link协议) |
|||
|
|||
## ip地址-InetAddress类 |
|||
|
|||
* 唯一的标识Internet上的计算机(通信实体) |
|||
* 本地地址(hostAddress):127.0.0.1,主机名(hostName);localhost |
|||
* IPV4和IPV6 |
|||
* IPV4:4个字节组成,4个0-255 |
|||
* IPV6:128位(16个字节),写成8个无符号整数,每个整数用四个十六进制位表示 |
|||
* 公网地址和私有地址:192.168.开头的对应的是私有地址 |
|||
* 域名:如:www.baidu.com,域名先找本机hosts文件查找对应的ip地址,如果未找到会经过域名解析服务器DNS进行解析成IP地址,从而访问网络服务器 |
|||
|
|||
```java |
|||
public class InetAdressTest { |
|||
public static void main(String[] args) { |
|||
try { |
|||
//经过ip地址 |
|||
InetAddress byAddress1 = InetAddress.getByName("192.168.1.1"); |
|||
System.out.println(byAddress1); |
|||
//通过域名 |
|||
InetAddress byName = InetAddress.getByName("www.baidu.com"); |
|||
System.out.println(byName); |
|||
//本地回路地址127.0.0.1 域名localhost |
|||
InetAddress localhost = InetAddress.getByName("localhost"); |
|||
System.out.println(localhost); |
|||
//直接获取本机地址、本机回路地址、本机域名 |
|||
System.out.println(InetAddress.getLocalHost()); |
|||
System.out.println(localhost.getHostAddress()); |
|||
System.out.println(localhost.getHostName()); |
|||
} catch (UnknownHostException e) { |
|||
e.printStackTrace(); |
|||
} |
|||
} |
|||
} |
|||
//输出:/192.168.1.1 |
|||
// www.baidu.com/180.101.49.11 |
|||
// localhost/127.0.0.1 |
|||
// DESKTOP-JRHETO1/192.168.1.13 |
|||
// 127.0.0.1 |
|||
// localhost |
|||
``` |
|||
|
|||
## 端口 |
|||
|
|||
* 端口号标识正在计算机上运行的进程(程序) |
|||
|
|||
* 不同的进程有不同的端口号 |
|||
|
|||
* 端口号为一个16位的整数 |
|||
|
|||
* 端口分类: |
|||
|
|||
* 公认端口:0-1023,被预先定义的服务通信端口占用(如HTTP占用80,FTP占用21,Telnet占用23) |
|||
|
|||
* 注册端口:1024-49151,分配给用户进程或应用程序(如Tomcat占用8080,MySQL占用3306,Oracle占用1521) |
|||
* 动态/私有端口:59152-65535 |
|||
|
|||
**端口号和IP地址组合得到一个网络套接字:Socket** |
|||
|
|||
## 网络协议 |
|||
|
|||
> 计算机网络中实现通信必须遵守的约定,即通信协议,对速率、传输代码、代码结构、传输控制步骤、出错控制等指定标准 |
|||
|
|||
|
|||
|
|||
**通信协议分层思想**:在指定协议时,把复杂成分分解成一些简单的成分,再进行复合。常用的复合方式是层次方式,即同层间可以通信、上一层可以调用下一层、隔层不能通信。各层互不影响 |
|||
|
|||
**传输层两个重要协议:** |
|||
|
|||
1. 传输控制协议TCP:Transmission Control Protocol |
|||
2. 用户数据报协议UDP:User Datagram Protocol |
|||
|
|||
## TCP/IP协议簇 |
|||
|
|||
TCP/IP是两个主要协议:传输层协议TCP和网络互联协议IP命名,实际上是一组协议,包括多个具有不同功能且互为关联的协议 |
|||
|
|||
1. 传输控制协议TCP:Transmission Control Protocol |
|||
2. IP(Internet Protocol):网络层的主要协议,支持网络间互联的数据通信 |
|||
|
|||
TCP/IP协议模型从更实用的角度出发,形成了高效的四层体系结构: |
|||
|
|||
1. 物理链路层 |
|||
2. IP层(网络层) |
|||
3. 传输层 |
|||
4. 应用层 |
|||
|
|||
# TCP和UDP |
|||
|
|||
## TCP |
|||
|
|||
### TCP特点 |
|||
|
|||
* 使用TCP前,需要建立TCP连接,形成传输数据通道 |
|||
* 采用**“三次握手”**方式,点对点通信,是可靠的通信 |
|||
|
|||
 |
|||
|
|||
* TCP协议进行通信的两个应用进程:客户端、服务端 |
|||
* 在连接中可进行大数据量的传输 |
|||
* 传输完毕,需要释放已经建立的连接,效率低,**“四次挥手”** |
|||
|
|||
 |
|||
|
|||
客户端和服务端均可以发起挥手动作(一般是客户端),在socket编程中,任何一方执行close()即可产生挥手操作 |
|||
|
|||
### TCP网络编程实例 |
|||
|
|||
```java |
|||
package com.tian.javastudy.InetAddressDemo; |
|||
/* |
|||
* TCP网络编程 |
|||
* 客户端发送数据给服务端,服务端在控制台显示输出 |
|||
* */ |
|||
import org.junit.Test; |
|||
import java.io.ByteArrayOutputStream; |
|||
import java.io.IOException; |
|||
import java.io.InputStream; |
|||
import java.io.OutputStream; |
|||
import java.net.InetAddress; |
|||
import java.net.ServerSocket; |
|||
import java.net.Socket; |
|||
import java.net.UnknownHostException; |
|||
|
|||
public class TCPTest1 { |
|||
//服务端 |
|||
@Test |
|||
public void server(){ |
|||
ServerSocket serverSocket = null; |
|||
Socket accept = null; |
|||
InputStream inputStream = null; |
|||
ByteArrayOutputStream baos = null; |
|||
try { |
|||
//创建服务端的serversocket,指明自己的端口号 |
|||
serverSocket = new ServerSocket(8899); |
|||
//调用accept()方法,接受来自客户端的socket |
|||
accept = serverSocket.accept(); |
|||
//获取一个输入流,并读取数据 |
|||
inputStream = accept.getInputStream(); |
|||
baos = new ByteArrayOutputStream(); |
|||
byte[] buffer = new byte[5]; |
|||
int len; |
|||
while ((len = inputStream.read(buffer)) != -1){ |
|||
baos.write(buffer,0,len); |
|||
} |
|||
System.out.println(baos.toString()); |
|||
//获取发送方的ip |
|||
System.out.println("发送方为:"+ accept.getInetAddress().getHostName()); |
|||
} catch (IOException e) { |
|||
e.printStackTrace(); |
|||
} finally { |
|||
//关闭资源 |
|||
if(baos != null){ |
|||
try { |
|||
baos.close(); |
|||
} catch (IOException e) { |
|||
e.printStackTrace(); |
|||
} |
|||
} |
|||
if(inputStream != null){ |
|||
try { |
|||
inputStream.close(); |
|||
} catch (IOException e) { |
|||
e.printStackTrace(); |
|||
} |
|||
} |
|||
if(accept != null){ |
|||
try { |
|||
accept.close(); |
|||
} catch (IOException e) { |
|||
e.printStackTrace(); |
|||
} |
|||
} |
|||
if(serverSocket != null){ |
|||
try { |
|||
serverSocket.close(); |
|||
} catch (IOException e) { |
|||
e.printStackTrace(); |
|||
} |
|||
} |
|||
} |
|||
} |
|||
|
|||
//客户端 |
|||
@Test |
|||
public void client() { |
|||
Socket socket = null; |
|||
OutputStream outputStream = null; |
|||
try { |
|||
//创建socket对象,指明服务器端的ip和端口号 |
|||
InetAddress inet = InetAddress.getByName("127.0.0.111"); |
|||
socket = new Socket(inet, 8899); |
|||
//获取一个输出流,并写出数据 |
|||
outputStream = socket.getOutputStream(); |
|||
outputStream.write("你好,我是客户端".getBytes()); |
|||
} catch (IOException e) { |
|||
e.printStackTrace(); |
|||
} finally { |
|||
//关闭资源 |
|||
if(outputStream!=null){ |
|||
try { |
|||
outputStream.close(); |
|||
} catch (IOException e) { |
|||
e.printStackTrace(); |
|||
} |
|||
} |
|||
if(socket!=null){ |
|||
try { |
|||
socket.close(); |
|||
} catch (IOException e) { |
|||
e.printStackTrace(); |
|||
} |
|||
} |
|||
} |
|||
} |
|||
} |
|||
/* |
|||
你好,我是客户端 |
|||
发送方为:127.0.0.1 |
|||
*/ |
|||
``` |
|||
|
|||
### 客户端-服务端 |
|||
|
|||
#### 客户端 |
|||
|
|||
* 自定义 |
|||
* 浏览器 |
|||
|
|||
#### 服务端 |
|||
|
|||
* 自定义 |
|||
* Tomcat服务器 |
|||
|
|||
## UDP |
|||
|
|||
#### 特点 |
|||
|
|||
* 将数据、源、目的地封装成数据包,不需要建立连接 |
|||
* 每个数据报的大小限制再64K内 |
|||
* 发送不管对方是否准备好,接收方收到也不确认,是不可靠的 |
|||
* 可以广播发送 |
|||
* 发送数据结束时无需释放资源,开销小,速度快 |
|||
|
|||
#### UDP网络编程 |
|||
|
|||
* 类DatagramSocket和DataGramPacket实现了基于UDP协议网络程序 |
|||
* UDP数据报通过数据报套接字DatagramSocket发送和接收,系统不保证UDP数据报一定能够安全送到目的地,也不确定什么时候可以送到 |
|||
* DataGramPacket对象封装了UDP数据报,在数据报中包含了发送端的IP地址和端口号以及接收端的IP地址和端口号 |
|||
* UDP协议中每个数据报都给出了完整的地址信息,因此无需建立发送方和接收方的连接,如同发快递包裹一样 |
|||
|
|||
```java |
|||
package com.tian.javastudy.InetAddressDemo; |
|||
|
|||
import org.junit.Test; |
|||
|
|||
import java.io.IOException; |
|||
import java.net.*; |
|||
|
|||
public class UDPTest1 { |
|||
//发送端 |
|||
@Test |
|||
public void sender() throws IOException { |
|||
//socket,无需包括接收方信息 |
|||
DatagramSocket socket = new DatagramSocket(); |
|||
//定义发送的信息 |
|||
String s = "我是发送方"; |
|||
//发送的字节长度 |
|||
byte[] bytes = s.getBytes(); |
|||
int len = bytes.length; |
|||
//目的ip,这里发送到本机 |
|||
InetAddress inet = InetAddress.getLocalHost(); |
|||
//DataGramPacket对象封装了UDP数据报,在数据报中包含了发送端的IP地址和端口号以及接收端的IP地址和端口号 |
|||
DatagramPacket packet = new DatagramPacket(bytes, 0, len, inet, 8899); |
|||
//发送 |
|||
socket.send(packet); |
|||
//关闭 |
|||
socket.close(); |
|||
} |
|||
|
|||
//接收方 |
|||
@Test |
|||
public void receiver() throws IOException { |
|||
//接收方端口 |
|||
DatagramSocket socket = new DatagramSocket(8899); |
|||
//DatagramSocket |
|||
byte[] bytes = new byte[100]; |
|||
DatagramPacket packet = new DatagramPacket(bytes,0,bytes.length); |
|||
//接受 |
|||
socket.receive(packet); |
|||
//保存数据,实际上已经存在了bytes数组中,但是不知道实际的长度 |
|||
String s = new String(packet.getData(),0,packet.getLength()); |
|||
//输出到控制台 |
|||
System.out.println(s); |
|||
} |
|||
} |
|||
/* |
|||
我是发送方 |
|||
*/ |
|||
``` |
|||
|
|||
# URL网络编程 |
|||
|
|||
## 特点 |
|||
|
|||
* URL(Uniform Resource Locator):统一资源定位符,表示Internet上某一资源的地址(种子) |
|||
* 通过URL我们可以访问Internet上的各种网络资源,比如最常见的www、ftp站点,浏览器通过解析给定的URL可以在网络上查找相应的文件或其他资源 |
|||
|
|||
## 基本结构 |
|||
|
|||
由五个部分组成:<传输协议>://<主机名>:<端口号>/<文件名>#片段名?参数列表 |
|||
|
|||
如:http://localhost:8080/examples/beauty.jpg |
|||
|
|||
* 传输协议:http |
|||
* 主机名:localhost |
|||
* 端口号:8080 |
|||
* 文件名:examples/beauty.jpg |
|||
* 片段名:即锚点,例如看小说,直接定位到章节 |
|||
* 参数列表格式:参数名=参数值&参数名=参数值 |
|||
|
|||
## 方法 |
|||
|
|||
 |
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
@ -0,0 +1,332 @@ |
|||
--- |
|||
title: 面向接口编程 |
|||
author: TianZD |
|||
top: true |
|||
cover: true |
|||
toc: true |
|||
mathjax: false |
|||
summary: 面向接口编程思想学习笔记,粗略学了一下,没有参考价值 |
|||
tags: |
|||
- 编程思想 |
|||
- 接口 |
|||
categories: |
|||
- java |
|||
- 转载 |
|||
reprintPolicy: cc_by |
|||
abbrlink: '14e0017' |
|||
date: 2022-04-29 10:58:42 |
|||
coverImg: |
|||
img: |
|||
password: |
|||
--- |
|||
|
|||
|
|||
|
|||
# 为什么我们要面向接口编程?! |
|||
|
|||
转载自程序羊的知乎文章 |
|||
|
|||
# 到底面向?编程 |
|||
|
|||
**面向过程编程(`Procedure Oriented`、简称`PO`)** 和 **面向对象编程(`Object Oriented`、简称`OO`)** 我们一定听过,然而实际企业级开发里受用更多的一种编程思想那就是:**面向接口编程(`Interface-Oriented`)**! |
|||
|
|||
接口这个概念我们一定不陌生,实际生活中**最常见的例子就是**:插座! |
|||
|
|||
我们只需要事先定义好插座的**接口标准**,各大插座厂商只要按这个接口标准生产,管你什么牌子、内部什么电路结构,这些均和用户无关,用户拿来就可以用;而且即使插座坏了,只要换一个符合接口标准的新插座,一切照样工作! |
|||
|
|||
|
|||
|
|||
 |
|||
|
|||
|
|||
|
|||
同理,实际代码设计也是这样! |
|||
|
|||
我们在设计一个软件的代码架构时,我们都希望**事先约定**好各个功能的**接口**(即:约定好接口签名和方法),实际开发时我们只需要实现这个接口就能完成具体的功能!后续即使项目变化、功能升级,程序员只需要按照接口约定重新实现一下,就可以达到系统升级和扩展的目的! |
|||
|
|||
正好,Java中天生就有`interface`这个语法,这简直是为面向接口编程而生的! |
|||
|
|||
所以接下来落实到代码上,举个通俗一点的小例子唠一唠,实际业务代码虽然比这个复杂,但原理是一模一样的。 |
|||
|
|||
------ |
|||
|
|||
## 做梦了 |
|||
|
|||
假如哪一天程序羊真发达了,一口豪气买了两辆豪车,一辆五菱宏光、一辆飞度、并且还专门聘请了一位驾驶员来帮助驾驶。 |
|||
|
|||
**两辆豪车在此:** |
|||
|
|||
```java |
|||
public class Wuling { |
|||
public void drive() { |
|||
System.out.println("驾驶五菱宏光汽车"); |
|||
} |
|||
} |
|||
|
|||
public class Fit { |
|||
public void drive() { |
|||
System.out.println("驾驶飞度汽车"); |
|||
} |
|||
} |
|||
``` |
|||
|
|||
**驾驶员定义在此:** |
|||
|
|||
驾驶员定义了两个`drive()`方法,分别用来驾驶两辆车: |
|||
|
|||
```text |
|||
public class Driver { |
|||
|
|||
public void drive( Wuling wuling ) { |
|||
wuling.drive(); // 驾驶五菱宏光的方法 |
|||
} |
|||
|
|||
public void drive( Fit fit ) { |
|||
fit.drive(); // 驾驶飞度的方法 |
|||
} |
|||
|
|||
// 用于测试功能的 main()函数 |
|||
public static void main( String[] args ) { |
|||
|
|||
// 实例化两辆新车 |
|||
Wuling wuling = new Wuling(); |
|||
Fit fit = new Fit(); |
|||
|
|||
// 实例化驾驶员 |
|||
Driver driver = new Driver(); |
|||
|
|||
driver.drive( wuling ); // 帮我开五菱宏光 |
|||
driver.drive( fit ); // 帮我开飞度 |
|||
} |
|||
} |
|||
``` |
|||
|
|||
这暂且看起来没问题!日子过得很融洽。 |
|||
|
|||
但后来过了段时间,程序羊又变得发达了一点,这次他又豪气地买了一辆新款奥拓(Alto)! |
|||
|
|||
可是现有的驾驶员类`Driver`的两个`drive()`方法里都开不了这辆新买的奥拓该怎么办呢? |
|||
|
|||
------ |
|||
|
|||
## 代码的灵活解耦 |
|||
|
|||
这时候,我想应该没有谁会专门再去往`Driver`类中添加一个新的`drive()`方法来达到目的吧?毕竟谁也不知道以后他还会不会买新车! |
|||
|
|||
这时候如果我希望我聘请的这位驾驶员对于所有车型都能驾驭,该怎么办呢? |
|||
|
|||
很容易想到,我们应该**做一层抽象**。毕竟不管是奥拓还是奥迪,它们都是汽车,因此我们**定义一个父类**叫做汽车类`Car`,里面只声明一个通用的`drive()`方法,具体怎么开先不用管: |
|||
|
|||
```text |
|||
// 抽象的汽车类Car,代表所有汽车 |
|||
public class Car { |
|||
void drive() { } // 通用的汽车驾驶方法 |
|||
} |
|||
``` |
|||
|
|||
这时,只要我新买的奥拓符合`Car`定义的驾驶标准即可被我的驾驶员驾驶,所以只需要新的奥拓来继承一下`Car`类即可: |
|||
|
|||
```text |
|||
public class Alto extends Car { |
|||
public void drive() { |
|||
System.out.println("驾驶奥拓汽车"); |
|||
} |
|||
} |
|||
``` |
|||
|
|||
同理,只需要我的驾驶员具备通用汽车`Car`的驾驶能力,那驾驶所有的汽车都不是问题,因此`Drvier`类的`drive()`方法只要传入的参数是**父类**,那就具备了通用性: |
|||
|
|||
```text |
|||
public class Driver { |
|||
|
|||
public void drive( Car car ) { // 方法参数使用父类来替代 |
|||
car.drive(); |
|||
} |
|||
|
|||
public static void main( String[] args ) { |
|||
Alto alto = new Alto(); |
|||
Driver driver = new Driver(); |
|||
driver.drive( alto ); |
|||
} |
|||
} |
|||
``` |
|||
|
|||
问题暂且解决了! |
|||
|
|||
------ |
|||
|
|||
但是再后来,程序羊他好像又更发达了一些,连车都不想坐了,想买一头驴(Donkey)让司机骑着带他出行! |
|||
|
|||
很明显,原先适用于汽车的`drive()`方法肯定是不适合骑驴的!但我们希望聘请的这位驾驶员既会开汽车,又会骑驴怎么办呢? |
|||
|
|||
害!我们干脆直接定义一个叫做交通工具(`TrafficTools`)的通用接口吧!里面包含一个通用的交通工具使用方法,管你是驾驶汽车,还是骑驴骑马,具体技能怎么实现先不管: |
|||
|
|||
```text |
|||
// 通用的交通工具接口定义 |
|||
public interface TrafficTools { |
|||
void drive(); // 通用的交通工具使用方法 |
|||
} |
|||
``` |
|||
|
|||
有了这个**接口约定**,接下来就好办了。我们让所有的`Car`、或者驴、马等,都来实现这个接口: |
|||
|
|||
```text |
|||
public class Car implements TrafficTools { |
|||
@Override |
|||
public void drive() { } |
|||
} |
|||
|
|||
public class Wuling extends Car { |
|||
public void drive() { |
|||
System.out.println("驾驶五菱宏光汽车"); |
|||
} |
|||
} |
|||
|
|||
public class Fit extends Car { |
|||
public void drive() { |
|||
System.out.println("驾驶飞度汽车"); |
|||
} |
|||
} |
|||
|
|||
public class Alto extends Car { |
|||
public void drive() { |
|||
System.out.println("驾驶奥拓汽车"); |
|||
} |
|||
} |
|||
|
|||
public class Donkey implements TrafficTools { |
|||
@Override |
|||
public void drive() { |
|||
System.out.println("骑一头驴"); |
|||
} |
|||
} |
|||
``` |
|||
|
|||
这个时候只要我们的驾驶员师傅也**面向接口编程**,就没有任何问题: |
|||
|
|||
```text |
|||
public class Driver { |
|||
|
|||
// 方法参数面向接口编程 |
|||
public void drive( TrafficTools trafficTools ) { |
|||
trafficTools.drive(); |
|||
} |
|||
|
|||
public static void main( String[] args ) { |
|||
Driver driver = new Driver(); |
|||
driver.drive( new Wuling() ); // 开五菱 |
|||
driver.drive( new Fit() ); // 开飞度 |
|||
driver.drive( new Alto() ); // 开奥拓 |
|||
driver.drive( new Donkey() ); // 骑一头驴 |
|||
} |
|||
} |
|||
``` |
|||
|
|||
很明显,代码完全解耦了!这就是接口带来的便利。 |
|||
|
|||
------ |
|||
|
|||
## 代码的扩展性 |
|||
|
|||
面向接口编程的优点远不止上面这种代码解耦的场景,在实际企业开发里,利用接口思想**对已有代码进行灵活扩展**也特别常见。 |
|||
|
|||
再举一个例子:假设程序羊有一个非常豪气的朋友,叫:**程序牛**,他们家出行可不坐车,全靠私人飞机出行: |
|||
|
|||
```text |
|||
// 通用的飞机飞行接口 |
|||
public interface Plane { |
|||
void fly(); |
|||
} |
|||
|
|||
// 程序牛的专用机长,受过专业训练(即:实现了通用飞行接口) |
|||
public class PlaneDriver implements Plane { |
|||
@Override |
|||
public void fly() { |
|||
System.out.println("专业的飞行员操控飞机"); |
|||
} |
|||
} |
|||
|
|||
// 出门旅行 |
|||
public class Travel { |
|||
|
|||
// 此处函数参数也是面向接口编程!!! |
|||
public void fly( Plane plane ) { |
|||
plane.fly(); |
|||
} |
|||
|
|||
public static void main( String[] args ) { |
|||
Travel travel = new Travel(); // 开启一段旅行 |
|||
PlaneDriver planeDriver = new PlaneDriver(); // 聘请一个机长 |
|||
travel.fly( planeDriver ); // 由专业机长开飞机愉快的出去旅行 |
|||
} |
|||
} |
|||
``` |
|||
|
|||
但是突然有一天,他们家聘请的机长跳槽了,这时候程序牛一家就无法出行了,毕竟飞机不会驾驶。 |
|||
|
|||
于是他跑来问我借司机,想让我的驾驶员来帮他驾驶飞机出去旅行。 |
|||
|
|||
我一看,由于他们的代码面向的是接口,我就肯定地答应了他! |
|||
|
|||
这时候对我这边的扩展来说就非常容易了,我只需要安排我的驾驶员去培训一下飞行技能就OK了(实现一个方法就行): |
|||
|
|||
```text |
|||
// 让我的驾驶员去培训一下飞行技能(即:去实现通用飞行接口) |
|||
public class Driver implements Plane { |
|||
|
|||
public void drive( TrafficTools trafficTools ) { |
|||
trafficTools.drive(); |
|||
} |
|||
|
|||
// 实现了fly()方法,这下我的驾驶员也具备操控飞机的能力了! |
|||
@Override |
|||
public void fly() { |
|||
System.out.println("普通驾驶员操控飞机"); |
|||
} |
|||
} |
|||
``` |
|||
|
|||
这时候我的驾驶员`Driver`类就可以直接服务于他们一家的出行了: |
|||
|
|||
```text |
|||
public class Travel { |
|||
|
|||
public void fly( Plane plane ) { |
|||
plane.fly(); |
|||
} |
|||
|
|||
public static void main( String[] args ) { |
|||
Travel travel = new Travel(); |
|||
|
|||
// 专业飞行员操控飞机 |
|||
PlaneDriver planeDriver = new PlaneDriver(); |
|||
travel.fly( planeDriver ); |
|||
|
|||
// 普通驾驶员操控飞机 |
|||
Driver driver = new Driver(); |
|||
travel.fly( driver ); |
|||
} |
|||
} |
|||
``` |
|||
|
|||
看到没,这一改造过程中,我们只增加了代码,却并没有修改任何已有代码,就完成了代码扩展的任务,非常符合**开闭原则**! |
|||
|
|||
------ |
|||
|
|||
## 实际项目 |
|||
|
|||
实际开发中,我们就暂且不说诸如`Spring`这种框架内部会大量使用接口,并对外提供使用,就连我们自己平时写业务代码,我们也习惯于在`Service`层使用接口来进行一层隔离: |
|||
|
|||
|
|||
|
|||
 |
|||
|
|||
|
|||
|
|||
这种接口定义和具体实现逻辑的分开,非常有利于后续扩展和维护! |
|||
|
|||
------ |
|||
|
|||
## 小结 |
|||
|
|||
面向接口编程开发,对代码架构的解耦和扩展确实很有好处,这种编码思想也值得平时开发结合实践反复理解和回味! |
|||
File diff suppressed because it is too large
Loading…
Reference in new issue